 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Neural Network Acceleration on MPSoC board: Integrating SLAC's SNL, Rogue Software and Auto-SNL
Aug 29, 2025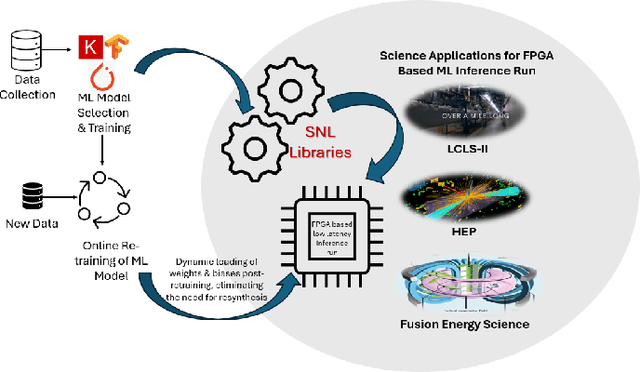
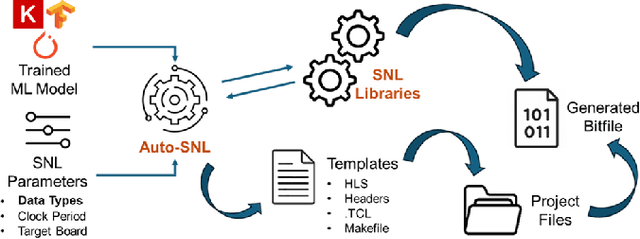
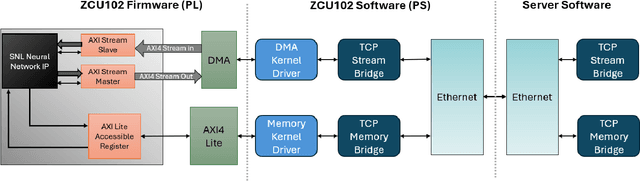
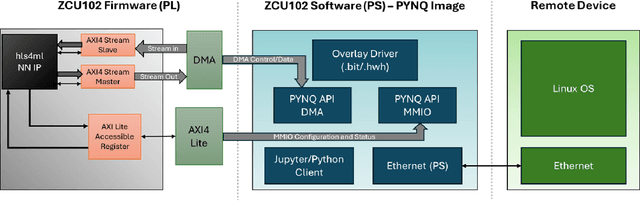
The LCLS-II Free Electron Laser (FEL) will generate X-ray pulses for beamline experiments at rates of up to 1~MHz, with detectors producing data throughputs exceeding 1 TB/s. Managing such massive data streams presents significant challenges, as transmission and storage infrastructures become prohibitively expensive. Machine learning (ML) offers a promising solution for real-time data reduction, but conventional implementations introduce excessive latency, making them unsuitable for high-speed experimental environments. To address these challenges, SLAC developed the SLAC Neural Network Library (SNL), a specialized framework designed to deploy real-time ML inference models on Field-Programmable Gate Arrays (FPGA). SNL's key feature is the ability to dynamically update model weights without requiring FPGA resynthesis, enhancing flexibility for adaptive learning applications. To further enhance usability and accessibility, we introduce Auto-SNL, a Python extension that streamlines the process of converting Python-based neural network models into SNL-compatible high-level synthesis code. This paper presents a benchmark comparison against hls4ml, the current state-of-the-art tool, across multiple neural network architectures, fixed-point precisions, and synthesis configurations targeting a Xilinx ZCU102 FPGA. The results showed that SNL achieves competitive or superior latency in most tested architectures, while in some cases also offering FPGA resource savings. This adaptation demonstrates SNL's versatility, opening new opportunities for researchers and academics in fields such as high-energy physics, medical imaging, robotics, and many more.
Embedded FPGA Developments in 130nm and 28nm CMOS for Machine Learning in Particle Detector Readout
Apr 26, 2024



Embedded field programmable gate array (eFPGA) technology allows the implementation of reconfigurable logic within the design of an application-specific integrated circuit (ASIC). This approach offers the low power and efficiency of an ASIC along with the ease of FPGA configuration, particularly beneficial for the use case of machine learning in the data pipeline of next-generation collider experiments. An open-source framework called "FABulous" was used to design eFPGAs using 130 nm and 28 nm CMOS technology nodes, which were subsequently fabricated and verified through testing. The capability of an eFPGA to act as a front-end readout chip was tested using simulation of high energy particles passing through a silicon pixel sensor. A machine learning-based classifier, designed for reduction of sensor data at the source, was synthesized and configured onto the eFPGA. A successful proof-of-concept was demonstrated through reproduction of the expected algorithm result on the eFPGA with perfect accuracy. Further development of the eFPGA technology and its application to collider detector readout is discussed.
Implementation of a framework for deploying AI inference engines in FPGAs
May 30, 2023The LCLS2 Free Electron Laser FEL will generate xray pulses to beamline experiments at up to 1Mhz These experimentals will require new ultrahigh rate UHR detectors that can operate at rates above 100 kHz and generate data throughputs upwards of 1 TBs a data velocity which requires prohibitively large investments in storage infrastructure Machine Learning has demonstrated the potential to digest large datasets to extract relevant insights however current implementations show latencies that are too high for realtime data reduction objectives SLAC has endeavored on the creation of a software framework which translates MLs structures for deployment on Field Programmable Gate Arrays FPGAs deployed at the Edge of the data chain close to the instrumentation This framework leverages Xilinxs HLS framework presenting an API modeled after the open source Keras interface to the TensorFlow library This SLAC Neural Network Library SNL framework is designed with a streaming data approach optimizing the data flow between layers while minimizing the buffer data buffering requirements The goal is to ensure the highest possible framerate while keeping the maximum latency constrained to the needs of the experiment Our framework is designed to ensure the RTL implementation of the network layers supporting full redeployment of weights and biases without requiring resynthesis after training The ability to reduce the precision of the implemented networks through quantization is necessary to optimize the use of both DSP and memory resources in the FPGA We currently have a preliminary version of the toolset and are experimenting with both general purpose example networks and networks being designed for specific LCLS2 experiments.