 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmSnap: Bayesian One-Shot Fusion in a Self-Calibrated mmWave Radar Network
May 01, 2025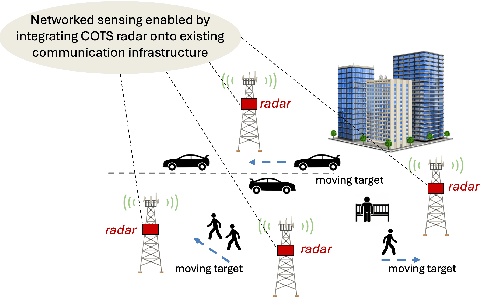
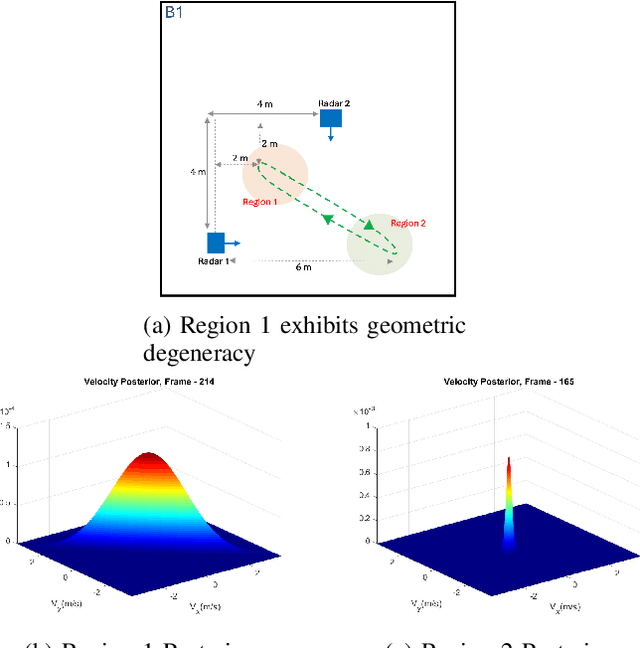
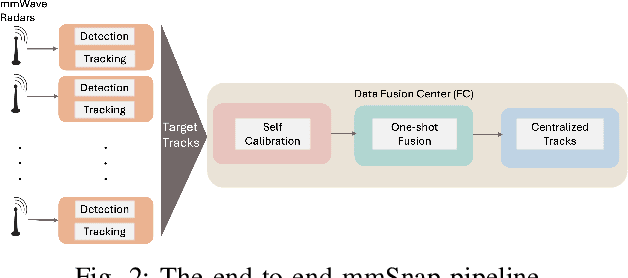

We present mmSnap, a collaborative RF sensing framework using multiple radar nodes, and demonstrate its feasibility and efficacy using commercially available mmWave MIMO radars. Collaborative fusion requires network calibration, or estimates of the relative poses (positions and orientations) of the sensors. We experimentally validate a self-calibration algorithm developed in our prior work, which estimates relative poses in closed form by least squares matching of target tracks within the common field of view (FoV). We then develop and demonstrate a Bayesian framework for one-shot fusion of measurements from multiple calibrated nodes, which yields instantaneous estimates of position and velocity vectors that match smoothed estimates from multi-frame tracking. Our experiments, conducted outdoors with two radar nodes tracking a moving human target, validate the core assumptions required to develop a broader set of capabilities for networked sensing with opportunistically deployed nodes.
A Novel Approach to OCR using Image Recognition based Classification for Ancient Tamil Inscriptions in Temples
Jul 04, 2019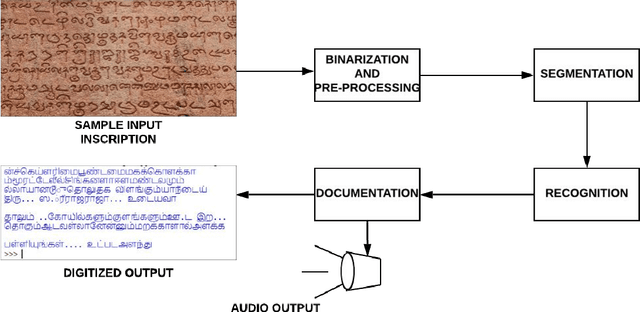

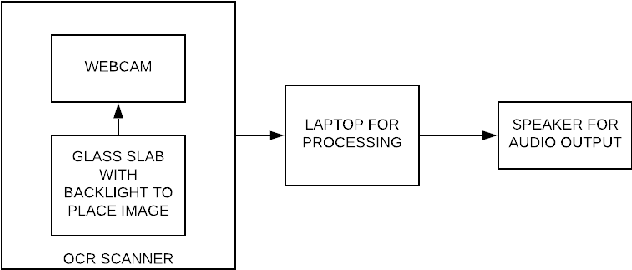
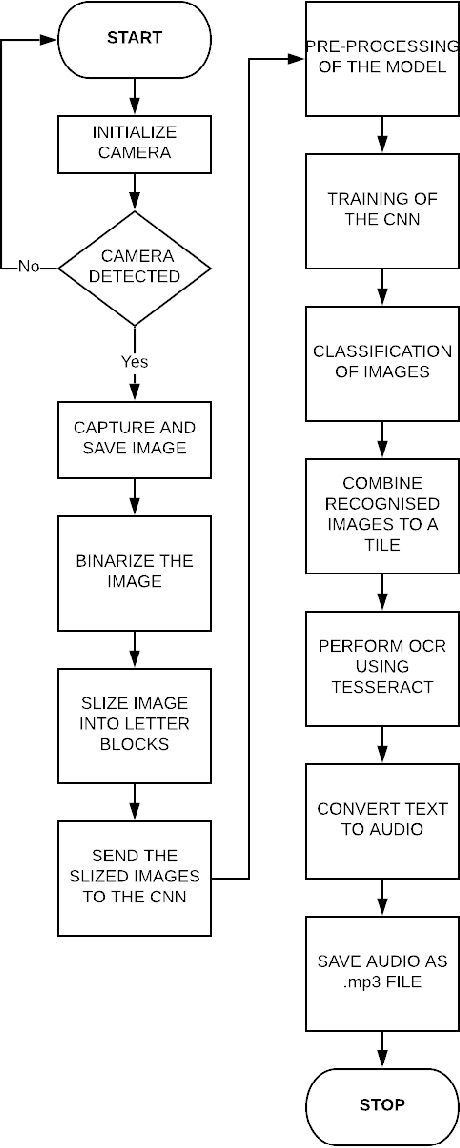
Recognition of ancient Tamil characters has always been a challenge for epigraphers. This is primarily because the language has evolved over the several centuries and the character set over this time has both expanded and diversified. This proposed work focuses on improving optical character recognition techniques for ancient Tamil script which was in use between the 7th and 12th centuries. While comprehensively curating a functional data set for ancient Tamil characters is an arduous task, in this work, a data set has been curated using cropped images of characters found on certain temple inscriptions, specific to this time as a case study. After using Otsu thresholding method for binarization of the image a two dimensional convolution neural network is defined and used to train, classify and, recognize the ancient Tamil characters. To implement the optical character recognition techniques, the neural network is linked to the Tesseract using the pytesseract library of Python. As an added feature, the work also incorporates Google's text to speech voice engine to produce an audio output of the digitized text. Various samples for both modern and ancient Tamil were collected and passed through the system. It is found that for Tamil inscriptions studied over the considered time period, a combined efficiency of 77.7 percent can be achieved.