 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D modelling of survey scene from images enhanced with a multi-exposure fusion
Nov 10, 2021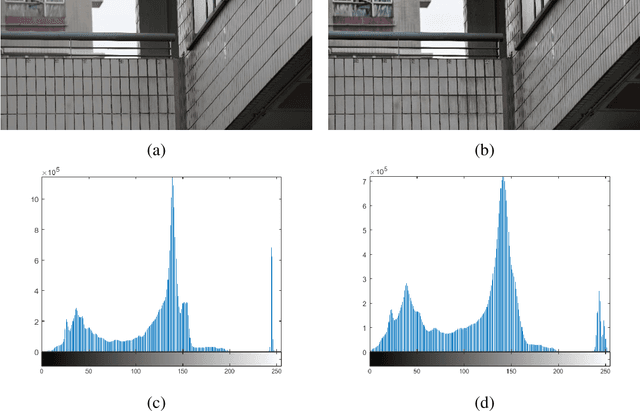
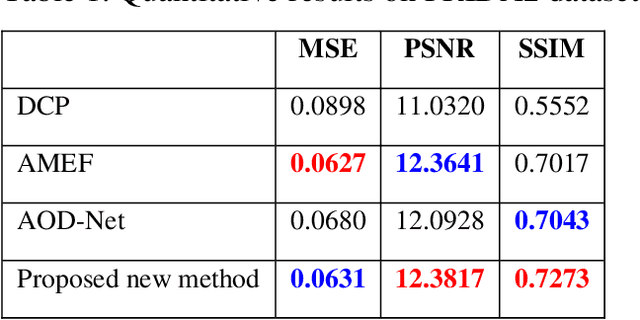

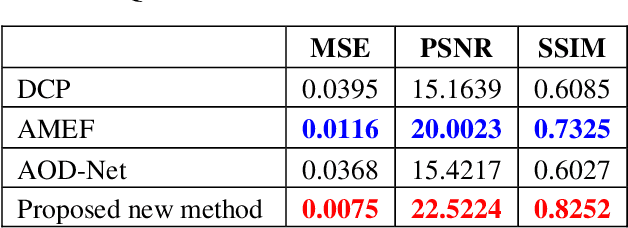
In current practice, scene survey is carried out by workers using total stations. The method has high accuracy, but it incurs high costs if continuous monitoring is needed. Techniques based on photogrammetry, with the relatively cheaper digital cameras, have gained wide applications in many fields. Besides point measurement, photogrammetry can also create a three-dimensional (3D) model of the scene. Accurate 3D model reconstruction depends on high quality images. Degraded images will result in large errors in the reconstructed 3D model. In this paper, we propose a method that can be used to improve the visibility of the images, and eventually reduce the errors of the 3D scene model. The idea is inspired by image dehazing. Each original image is first transformed into multiple exposure images by means of gamma-correction operations and adaptive histogram equalization. The transformed images are analyzed by the computation of the local binary patterns. The image is then enhanced, with each pixel generated from the set of transformed image pixels weighted by a function of the local pattern feature and image saturation. Performance evaluation has been performed on benchmark image dehazing datasets. Experimentations have been carried out on outdoor and indoor surveys. Our analysis finds that the method works on different types of degradation that exist in both outdoor and indoor images. When fed into the photogrammetry software, the enhanced images can reconstruct 3D scene models with sub-millimeter mean errors.
Saliency detection with moving camera via background model completion
Oct 30, 2021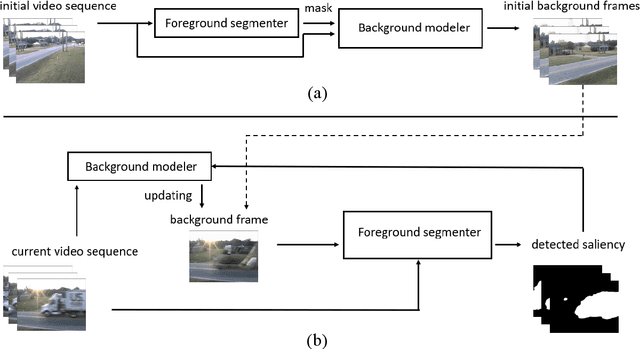
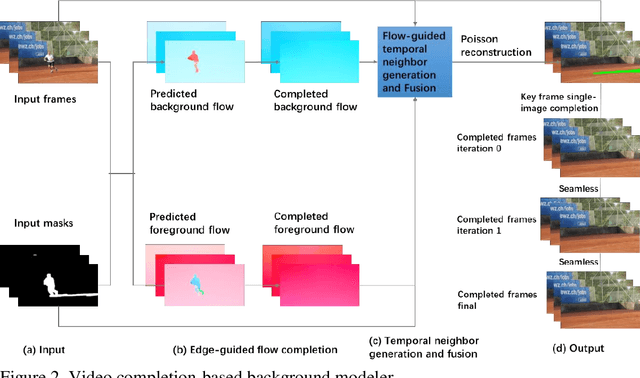


To detect saliency in video is a fundamental step in many computer vision systems. Saliency is the significant target(s) in the video. The object of interest is further analyzed for high-level applications. The segregation of saliency and the background can be made if they exhibit different visual cues. Therefore, saliency detection is often formulated as background subtraction. However, saliency detection is challenging. For instance, dynamic background can result in false positive errors. In another scenario, camouflage will lead to false negative errors. With moving camera, the captured scenes are even more complicated to handle. We propose a new framework, called saliency detection via background model completion (SD-BMC), that comprises of a background modeler and the deep learning background/foreground segmentation network. The background modeler generates an initial clean background image from a short image sequence. Based on the idea of video completion, a good background frame can be synthesized with the co-existence of changing background and moving objects. We adopt the background/foreground segmenter, although pre-trained with a specific video dataset, can also detect saliency in unseen videos. The background modeler can adjust the background image dynamically when the background/foreground segmenter output deteriorates during processing of a long video. To the best of our knowledge, our framework is the first one to adopt video completion for background modeling and saliency detection in videos captured by moving camera. The results, obtained from the PTZ videos, show that our proposed framework outperforms some deep learning-based background subtraction models by 11% or more. With more challenging videos, our framework also outperforms many high ranking background subtraction methods by more than 3%.