 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Convolutional Neural Networks via Meta Orthogonalization
Nov 15, 2020
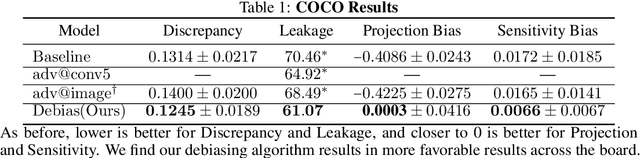


While deep learning models often achieve strong task performance, their successes are hampered by their inability to disentangle spurious correlations from causative factors, such as when they use protected attributes (e.g., race, gender, etc.) to make decisions. In this work, we tackle the problem of debiasing convolutional neural networks (CNNs) in such instances. Building off of existing work on debiasing word embeddings and model interpretability, our Meta Orthogonalization method encourages the CNN representations of different concepts (e.g., gender and class labels) to be orthogonal to one another in activation space while maintaining strong downstream task performance. Through a variety of experiments, we systematically test our method and demonstrate that it significantly mitigates model bias and is competitive against current adversarial debiasing methods.
GANchors: Realistic Image Perturbation Distributions for Anchors Using Generative Models
Jun 01, 2019
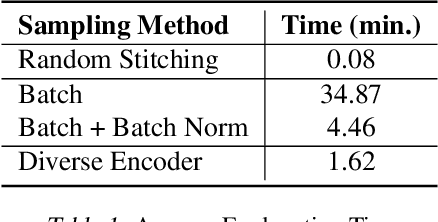


We extend and improve the work of Model Agnostic Anchors for explanations on image classification through the use of generative adversarial networks (GANs). Using GANs, we generate samples from a more realistic perturbation distribution, by optimizing under a lower dimensional latent space. This increases the trust in an explanation, as results now come from images that are more likely to be found in the original training set of a classifier, rather than an overlay of random images. A large drawback to our method is the computational complexity of sampling through optimization; to address this, we implement more efficient algorithms, including a diverse encoder. Lastly, we share results from the MNIST and CelebA datasets, and note that our explanations can lead to smaller and higher precision anchors.