 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adversarial Input Generation via Neural Net Patching
Nov 30, 2022The adversarial input generation problem has become central in establishing the robustness and trustworthiness of deep neural nets, especially when they are used in safety-critical application domains such as autonomous vehicles and precision medicine. This is also practically challenging for multiple reasons-scalability is a common issue owing to large-sized networks, and the generated adversarial inputs often lack important qualities such as naturalness and output-impartiality. We relate this problem to the task of patching neural nets, i.e. applying small changes in some of the network$'$s weights so that the modified net satisfies a given property. Intuitively, a patch can be used to produce an adversarial input because the effect of changing the weights can also be brought about by changing the inputs instead. This work presents a novel technique to patch neural networks and an innovative approach of using it to produce perturbations of inputs which are adversarial for the original net. We note that the proposed solution is significantly more effective than the prior state-of-the-art techniques.
Efficiently Finding Adversarial Examples with DNN Preprocessing
Nov 16, 2022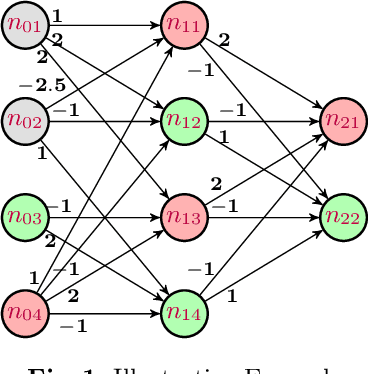
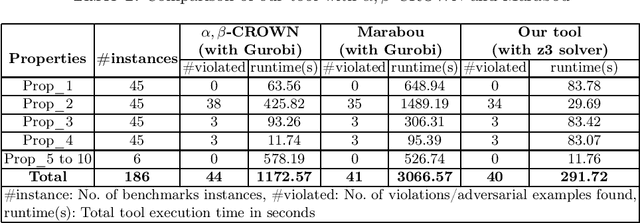
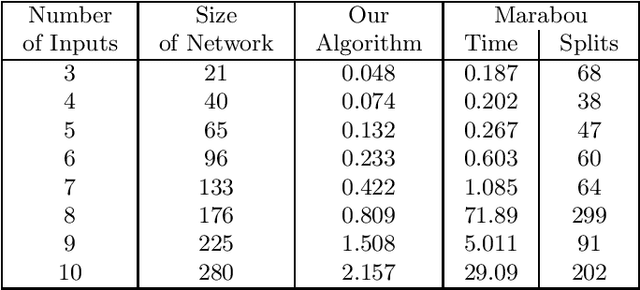
Deep Neural Networks (DNNs) are everywhere, frequently performing a fairly complex task that used to be unimaginable for machines to carry out. In doing so, they do a lot of decision making which, depending on the application, may be disastrous if gone wrong. This necessitates a formal argument that the underlying neural networks satisfy certain desirable properties. Robustness is one such key property for DNNs, particularly if they are being deployed in safety or business critical applications. Informally speaking, a DNN is not robust if very small changes to its input may affect the output in a considerable way (e.g. changes the classification for that input). The task of finding an adversarial example is to demonstrate this lack of robustness, whenever applicable. While this is doable with the help of constrained optimization techniques, scalability becomes a challenge due to large-sized networks. This paper proposes the use of information gathered by preprocessing the DNN to heavily simplify the optimization problem. Our experiments substantiate that this is effective, and does significantly better than the state-of-the-art.
Permutation Invariance of Deep Neural Networks with ReLUs
Oct 18, 2021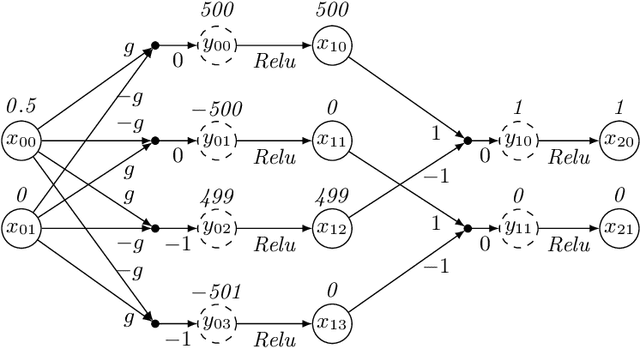
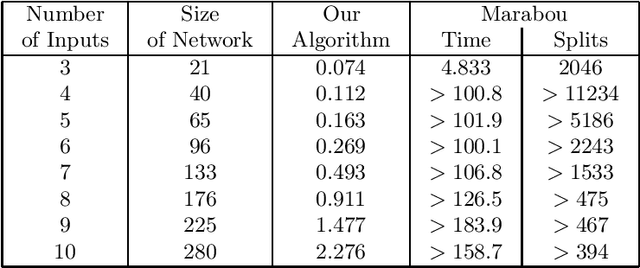
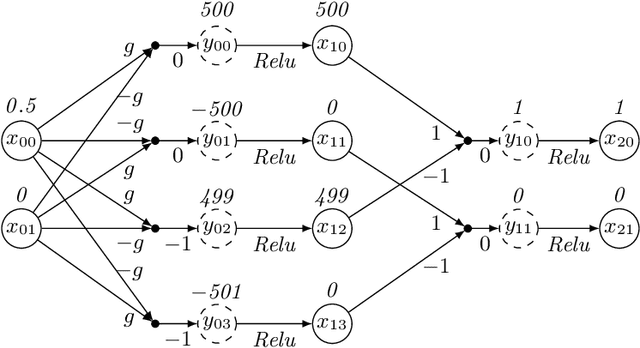
Consider a deep neural network (DNN) that is being used to suggest the direction in which an aircraft must turn to avoid a possible collision with an intruder aircraft. Informally, such a network is well-behaved if it asks the own ship to turn right (left) when an intruder approaches from the left (right). Consider another network that takes four inputs -- the cards dealt to the players in a game of contract bridge -- and decides which team can bid game. Loosely speaking, if you exchange the hands of partners (north and south, or east and west), the decision would not change. However, it will change if, say, you exchange north's hand with east. This permutation invariance property, for certain permutations at input and output layers, is central to the correctness and robustness of these networks. This paper proposes a sound, abstraction-based technique to establish permutation invariance in DNNs with ReLU as the activation function. The technique computes an over-approximation of the reachable states, and an under-approximation of the safe states, and propagates this information across the layers, both forward and backward. The novelty of our approach lies in a useful tie-class analysis, that we introduce for forward propagation, and a scalable 2-polytope under-approximation method that escapes the exponential blow-up in the number of regions during backward propagation. An experimental comparison shows the efficiency of our algorithm over that of verifying permutation invariance as a two-safety property (using FFNN verification over two copies of the network).