 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hamiltonian Monte Carlo Model for Imputation and Augmentation of Healthcare Data
Mar 03, 2021
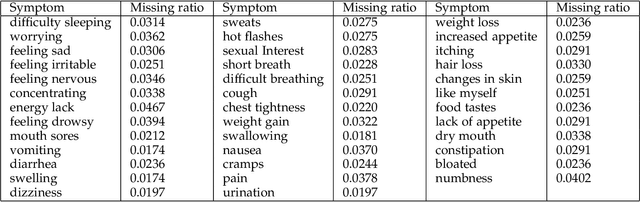

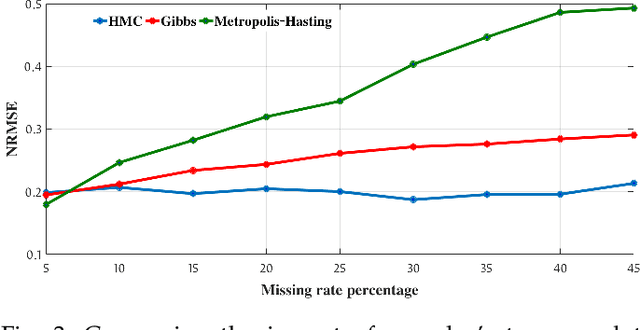
Missing values exist in nearly all clinical studies because data for a variable or question are not collected or not available. Inadequate handling of missing values can lead to biased results and loss of statistical power in analysis. Existing models usually do not consider privacy concerns or do not utilise the inherent correlations across multiple features to impute the missing values. In healthcare applications, we are usually confronted with high dimensional and sometimes small sample size datasets that need more effective augmentation or imputation techniques. Besides, imputation and augmentation processes are traditionally conducted individually. However, imputing missing values and augmenting data can significantly improve generalisation and avoid bias in machine learning models. A Bayesian approach to impute missing values and creating augmented samples in high dimensional healthcare data is proposed in this work. We propose folded Hamiltonian Monte Carlo (F-HMC) with Bayesian inference as a more practical approach to process the cross-dimensional relations by applying a random walk and Hamiltonian dynamics to adapt posterior distribution and generate large-scale samples. The proposed method is applied to a cancer symptom assessment dataset and confirmed to enrich the quality of data in precision, accuracy, recall, F1 score, and propensity metric.