 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiFT: Lightweight, FPGA-tailored 3D object detection based on LiDAR data
Jan 19, 2025This paper presents LiFT, a lightweight, fully quantized 3D object detection algorithm for LiDAR data, optimized for real-time inference on FPGA platforms. Through an in-depth analysis of FPGA-specific limitations, we identify a set of FPGA-induced constraints that shape the algorithm's design. These include a computational complexity limit of 30 GMACs (billion multiply-accumulate operations), INT8 quantization for weights and activations, 2D cell-based processing instead of 3D voxels, and minimal use of skip connections. To meet these constraints while maximizing performance, LiFT combines novel mechanisms with state-of-the-art techniques such as reparameterizable convolutions and fully sparse architecture. Key innovations include the Dual-bound Pillar Feature Net, which boosts performance without increasing complexity, and an efficient scheme for INT8 quantization of input features. With a computational cost of just 20.73 GMACs, LiFT stands out as one of the few algorithms targeting minimal-complexity 3D object detection. Among comparable methods, LiFT ranks first, achieving an mAP of 51.84% and an NDS of 61.01% on the challenging NuScenes validation dataset. The code will be available at https://github.com/vision-agh/lift.
Comparative study of subset selection methods for rapid prototyping of 3D object detection algorithms
Jun 30, 2023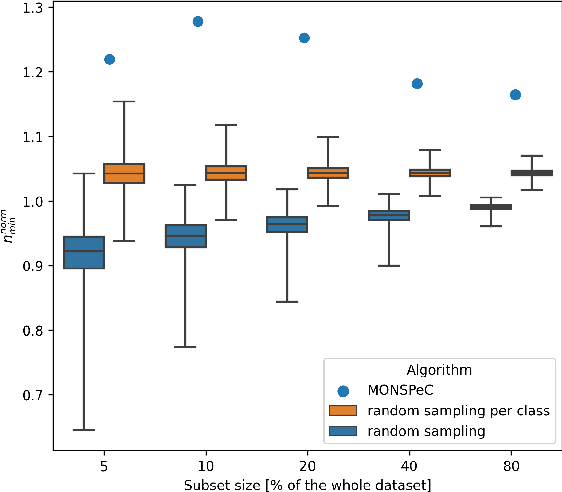
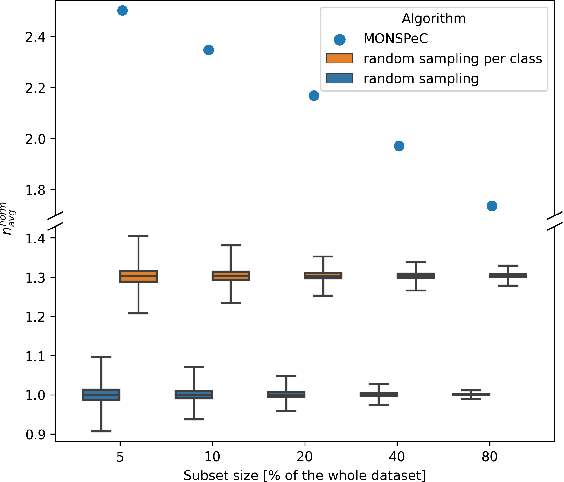
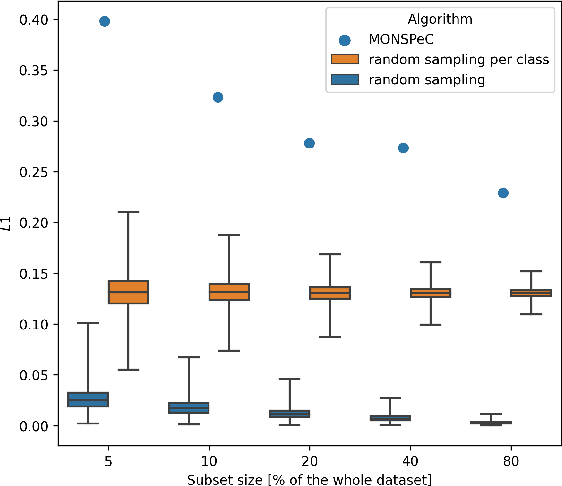
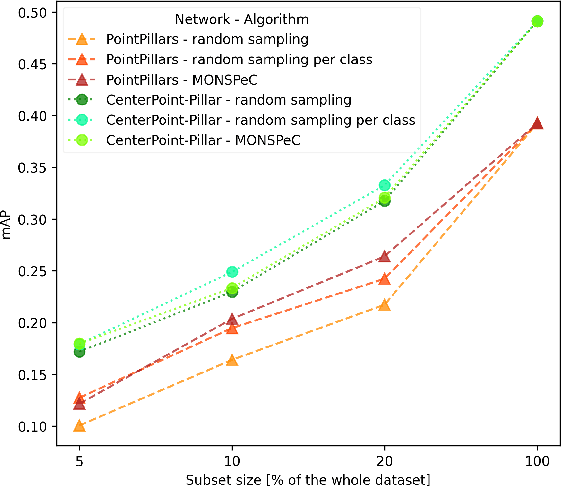
Object detection in 3D is a crucial aspect in the context of autonomous vehicles and drones. However, prototyping detection algorithms is time-consuming and costly in terms of energy and environmental impact. To address these challenges, one can check the effectiveness of different models by training on a subset of the original training set. In this paper, we present a comparison of three algorithms for selecting such a subset - random sampling, random per class sampling, and our proposed MONSPeC (Maximum Object Number Sampling per Class). We provide empirical evidence for the superior effectiveness of random per class sampling and MONSPeC over basic random sampling. By replacing random sampling with one of the more efficient algorithms, the results obtained on the subset are more likely to transfer to the results on the entire dataset. The code is available at: https://github.com/vision-agh/monspec.
PointPillars Backbone Type Selection For Fast and Accurate LiDAR Object Detection
Sep 30, 2022
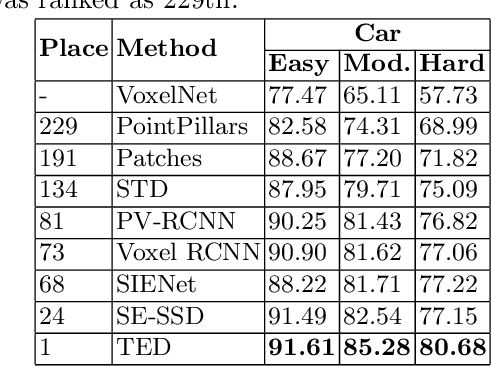
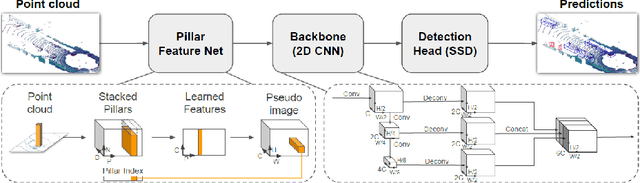
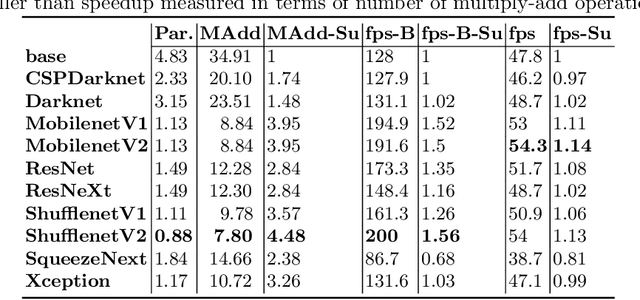
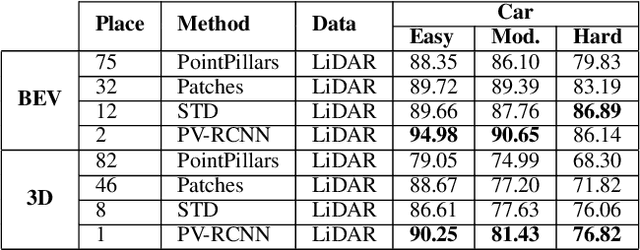
3D object detection from LiDAR sensor data is an important topic in the context of autonomous cars and drones. In this paper, we present the results of experiments on the impact of backbone selection of a deep convolutional neural network on detection accuracy and computation speed. We chose the PointPillars network, which is characterised by a simple architecture, high speed, and modularity that allows for easy expansion. During the experiments, we paid particular attention to the change in detection efficiency (measured by the mAP metric) and the total number of multiply-addition operations needed to process one point cloud. We tested 10 different convolutional neural network architectures that are widely used in image-based detection problems. For a backbone like MobilenetV1, we obtained an almost 4x speedup at the cost of a 1.13% decrease in mAP. On the other hand, for CSPDarknet we got an acceleration of more than 1.5x at an increase in mAP of 0.33%. We have thus demonstrated that it is possible to significantly speed up a 3D object detector in LiDAR point clouds with a small decrease in detection efficiency. This result can be used when PointPillars or similar algorithms are implemented in embedded systems, including SoC FPGAs. The code is available at https://github.com/vision-agh/pointpillars\_backbone.
Optimisation of the PointPillars network for 3D object detection in point clouds
Jul 01, 2020
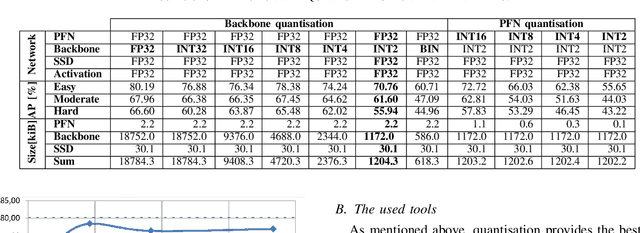
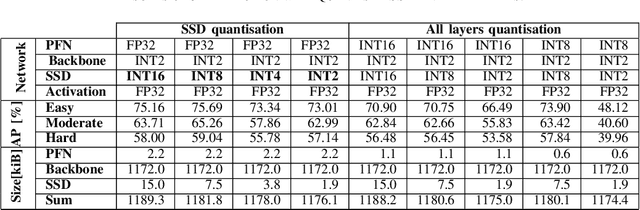
In this paper we present our research on the optimisation of a deep neural network for 3D object detection in a point cloud. Techniques like quantisation and pruning available in the Brevitas and PyTorch tools were used. We performed the experiments for the PointPillars network, which offers a reasonable compromise between detection accuracy and calculation complexity. The aim of this work was to propose a variant of the network which we will ultimately implement in an FPGA device. This will allow for real-time LiDAR data processing with low energy consumption. The obtained results indicate that even a significant quantisation from 32-bit floating point to 2-bit integer in the main part of the algorithm, results in 5%-9% decrease of the detection accuracy, while allowing for almost a 16-fold reduction in size of the model.