 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQANA: LLM-based Question Generation and Network Analysis for Zero-shot Key Point Analysis and Beyond
Apr 29, 2024The proliferation of social media has led to information overload and increased interest in opinion mining. We propose "Question-Answering Network Analysis" (QANA), a novel opinion mining framework that utilizes Large Language Models (LLMs) to generate questions from users' comments, constructs a bipartite graph based on the comments' answerability to the questions, and applies centrality measures to examine the importance of opinions. We investigate the impact of question generation styles, LLM selections, and the choice of embedding model on the quality of the constructed QA networks by comparing them with annotated Key Point Analysis datasets. QANA achieves comparable performance to previous state-of-the-art supervised models in a zero-shot manner for Key Point Matching task, also reducing the computational cost from quadratic to linear. For Key Point Generation, questions with high PageRank or degree centrality align well with manually annotated key points. Notably, QANA enables analysts to assess the importance of key points from various aspects according to their selection of centrality measure. QANA's primary contribution lies in its flexibility to extract key points from a wide range of perspectives, which enhances the quality and impartiality of opinion mining.
Beyond Real-world Benchmark Datasets: An Empirical Study of Node Classification with GNNs
Jun 18, 2022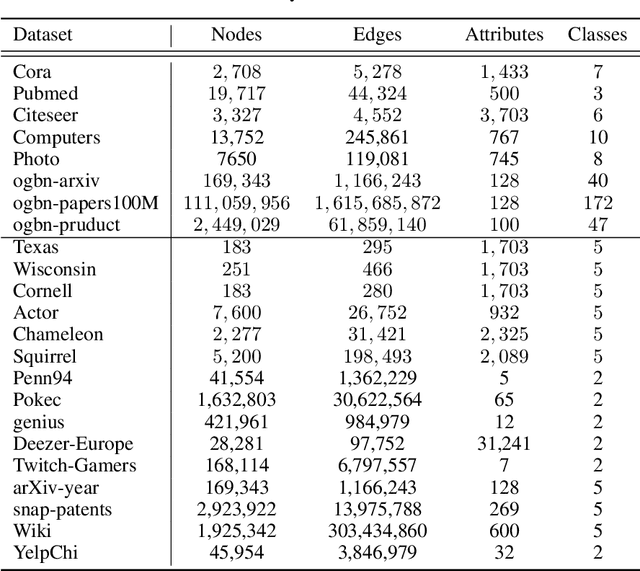
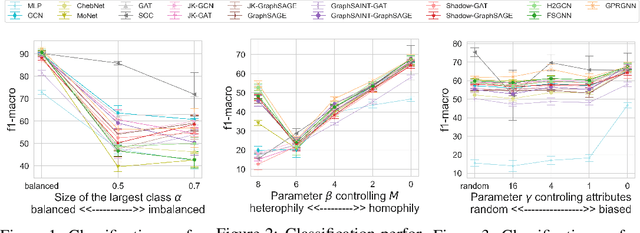

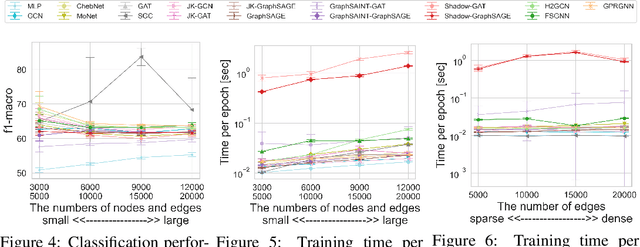
Graph Neural Networks (GNNs) have achieved great success on a node classification task. Despite the broad interest in developing and evaluating GNNs, they have been assessed with limited benchmark datasets. As a result, the existing evaluation of GNNs lacks fine-grained analysis from various characteristics of graphs. Motivated by this, we conduct extensive experiments with a synthetic graph generator that can generate graphs having controlled characteristics for fine-grained analysis. Our empirical studies clarify the strengths and weaknesses of GNNs from four major characteristics of real-world graphs with class labels of nodes, i.e., 1) class size distributions (balanced vs. imbalanced), 2) edge connection proportions between classes (homophilic vs. heterophilic), 3) attribute values (biased vs. random), and 4) graph sizes (small vs. large). In addition, to foster future research on GNNs, we publicly release our codebase that allows users to evaluate various GNNs with various graphs. We hope this work offers interesting insights for future research.