 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Extraction of Human Motion Structures via Frame-wise Discrete Features
Sep 12, 2023



The present paper proposes an encoder-decoder model for extracting the structures of human motions represented by frame-wise discrete features in a self-supervised manner. In the proposed method, features are extracted as codes in a motion codebook without the use of human knowledge, and the relationship between these codes can be visualized on a graph. Since the codes are expected to be temporally sparse compared to the captured frame rate and can be shared by multiple sequences, the proposed network model also addresses the need for training constraints. Specifically, the model consists of self-attention layers and a vector clustering block. The attention layers contribute to finding sparse keyframes and discrete features as motion codes, which are then extracted by vector clustering. The constraints are realized as training losses so that the same motion codes can be as contiguous as possible and can be shared by multiple sequences. In addition, we propose the use of causal self-attention as a method by which to calculate attention for long sequences consisting of numerous frames. In our experiments, the sparse structures of motion codes were used to compile a graph that facilitates visualization of the relationship between the codes and the differences between sequences. We then evaluated the effectiveness of the extracted motion codes by applying them to multiple recognition tasks and found that performance levels comparable to task-optimized methods could be achieved by linear probing.
Skeleton Transformer Networks: 3D Human Pose and Skinned Mesh from Single RGB Image
Dec 29, 2018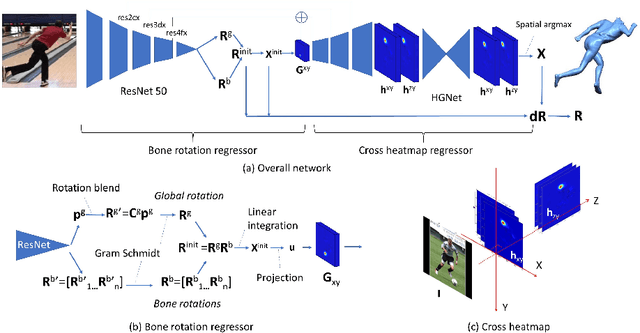
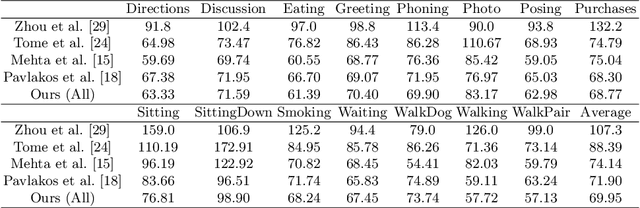


In this paper, we present Skeleton Transformer Networks (SkeletonNet), an end-to-end framework that can predict not only 3D joint positions but also 3D angular pose (bone rotations) of a human skeleton from a single color image. This in turn allows us to generate skinned mesh animations. Here, we propose a two-step regression approach. The first step regresses bone rotations in order to obtain an initial solution by considering skeleton structure. The second step performs refinement based on heatmap regressor using a 3D pose representation called cross heatmap which stacks heatmaps of xy and zy coordinates. By training the network using the proposed 3D human pose dataset that is comprised of images annotated with 3D skeletal angular poses, we showed that SkeletonNet can predict a full 3D human pose (joint positions and bone rotations) from a single image in-the-wild.