 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Non-Intrusive Detection of Adversarial Deep Learning Attacks via Observer Networks
Feb 22, 2020



Recent studies have shown that deep learning models are vulnerable to specifically crafted adversarial inputs that are quasi-imperceptible to humans. In this letter, we propose a novel method to detect adversarial inputs, by augmenting the main classification network with multiple binary detectors (observer networks) which take inputs from the hidden layers of the original network (convolutional kernel outputs) and classify the input as clean or adversarial. During inference, the detectors are treated as a part of an ensemble network and the input is deemed adversarial if at least half of the detectors classify it as so. The proposed method addresses the trade-off between accuracy of classification on clean and adversarial samples, as the original classification network is not modified during the detection process. The use of multiple observer networks makes attacking the detection mechanism non-trivial even when the attacker is aware of the victim classifier. We achieve a 99.5% detection accuracy on the MNIST dataset and 97.5% on the CIFAR-10 dataset using the Fast Gradient Sign Attack in a semi-white box setup. The number of false positive detections is a mere 0.12% in the worst case scenario.
Feature Losses for Adversarial Robustness
Dec 10, 2019
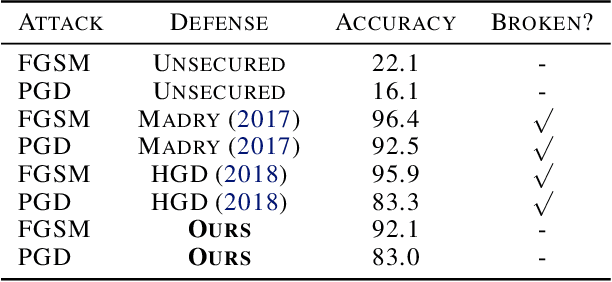


Deep learning has made tremendous advances in computer vision tasks such as image classification. However, recent studies have shown that deep learning models are vulnerable to specifically crafted adversarial inputs that are quasi-imperceptible to humans. In this work, we propose a novel approach to defending adversarial attacks. We employ an input processing technique based on denoising autoencoders as a defense. It has been shown that the input perturbations grow and accumulate as noise in feature maps while propagating through a convolutional neural network (CNN). We exploit the noisy feature maps by using an additional subnetwork to extract image feature maps and train an auto-encoder on perceptual losses of these feature maps. This technique achieves close to state-of-the-art results on defending MNIST and CIFAR10 datasets, but more importantly, shows a new way of employing a defense that cannot be trivially trained end-to-end by the attacker. Empirical results demonstrate the effectiveness of this approach on the MNIST and CIFAR10 datasets on simple as well as iterative LP attacks. Our method can be applied as a preprocessing technique to any off the shelf CNN.
Unsupervised Domain Alignment to Mitigate Low Level Dataset Biases
Jul 12, 2019



Dataset bias is a well-known problem in the field of computer vision. The presence of implicit bias in any image collection hinders a model trained and validated on a particular dataset to yield similar accuracies when tested on other datasets. In this paper, we propose a novel debiasing technique to reduce the effects of a biased training dataset. Our goal is to augment the training data using a generative network by learning a non-linear mapping from the source domain (training set) to the target domain (testing set) while retaining training set labels. The cycle consistency loss and adversarial loss for generative adversarial networks are used to learn the mapping. A structured similarity index (SSIM) loss is used to enforce label retention while augmenting the training set. Our methods and hypotheses are supported by quantitative comparisons with prior debiasing techniques. These comparisons showcase the superiority of our method and its potential to mitigate the effects of dataset bias during the inference stage.