 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn interpretable data-driven approach to optimizing clinical fall risk assessment
Jan 08, 2026In this study, we aim to better align fall risk prediction from the Johns Hopkins Fall Risk Assessment Tool (JHFRAT) with additional clinically meaningful measures via a data-driven modelling approach. We conducted a retrospective cohort analysis of 54,209 inpatient admissions from three Johns Hopkins Health System hospitals between March 2022 and October 2023. A total of 20,208 admissions were included as high fall risk encounters, and 13,941 were included as low fall risk encounters. To incorporate clinical knowledge and maintain interpretability, we employed constrained score optimization (CSO) models to reweight the JHFRAT scoring weights, while preserving its additive structure and clinical thresholds. Recalibration refers to adjusting item weights so that the resulting score can order encounters more consistently by the study's risk labels, and without changing the tool's form factor or deployment workflow. The model demonstrated significant improvements in predictive performance over the current JHFRAT (CSO AUC-ROC=0.91, JHFRAT AUC-ROC=0.86). This performance improvement translates to protecting an additional 35 high-risk patients per week across the Johns Hopkins Health System. The constrained score optimization models performed similarly with and without the EHR variables. Although the benchmark black-box model (XGBoost), improves upon the performance metrics of the knowledge-based constrained logistic regression (AUC-ROC=0.94), the CSO demonstrates more robustness to variations in risk labeling. This evidence-based approach provides a robust foundation for health systems to systematically enhance inpatient fall prevention protocols and patient safety using data-driven optimization techniques, contributing to improved risk assessment and resource allocation in healthcare settings.
Optimizing Clinical Fall Risk Prediction: A Data-Driven Integration of EHR Variables with the Johns Hopkins Fall Risk Assessment Tool
Oct 23, 2025In this study we aim to better align fall risk prediction from the Johns Hopkins Fall Risk Assessment Tool (JHFRAT) with additional clinically meaningful measures via a data-driven modelling approach. We conducted a retrospective analysis of 54,209 inpatient admissions from three Johns Hopkins Health System hospitals between March 2022 and October 2023. A total of 20,208 admissions were included as high fall risk encounters, and 13,941 were included as low fall risk encounters. To incorporate clinical knowledge and maintain interpretability, we employed constrained score optimization (CSO) models on JHFRAT assessment data and additional electronic health record (EHR) variables. The model demonstrated significant improvements in predictive performance over the current JHFRAT (CSO AUC-ROC=0.91, JHFRAT AUC-ROC=0.86). The constrained score optimization models performed similarly with and without the EHR variables. Although the benchmark black-box model (XGBoost), improves upon the performance metrics of the knowledge-based constrained logistic regression (AUC-ROC=0.94), the CSO demonstrates more robustness to variations in risk labelling. This evidence-based approach provides a robust foundation for health systems to systematically enhance inpatient fall prevention protocols and patient safety using data-driven optimization techniques, contributing to improved risk assessment and resource allocation in healthcare settings.
MedTsLLM: Leveraging LLMs for Multimodal Medical Time Series Analysis
Aug 14, 2024



The complexity and heterogeneity of data in many real-world applications pose significant challenges for traditional machine learning and signal processing techniques. For instance, in medicine, effective analysis of diverse physiological signals is crucial for patient monitoring and clinical decision-making and yet highly challenging. We introduce MedTsLLM, a general multimodal large language model (LLM) framework that effectively integrates time series data and rich contextual information in the form of text to analyze physiological signals, performing three tasks with clinical relevance: semantic segmentation, boundary detection, and anomaly detection in time series. These critical tasks enable deeper analysis of physiological signals and can provide actionable insights for clinicians. We utilize a reprogramming layer to align embeddings of time series patches with a pretrained LLM's embedding space and make effective use of raw time series, in conjunction with textual context. Given the multivariate nature of medical datasets, we develop methods to handle multiple covariates. We additionally tailor the text prompt to include patient-specific information. Our model outperforms state-of-the-art baselines, including deep learning models, other LLMs, and clinical methods across multiple medical domains, specifically electrocardiograms and respiratory waveforms. MedTsLLM presents a promising step towards harnessing the power of LLMs for medical time series analysis that can elevate data-driven tools for clinicians and improve patient outcomes.
An Open-Source Dataset on Dietary Behaviors and DASH Eating Plan Optimization Constraints
Oct 15, 2020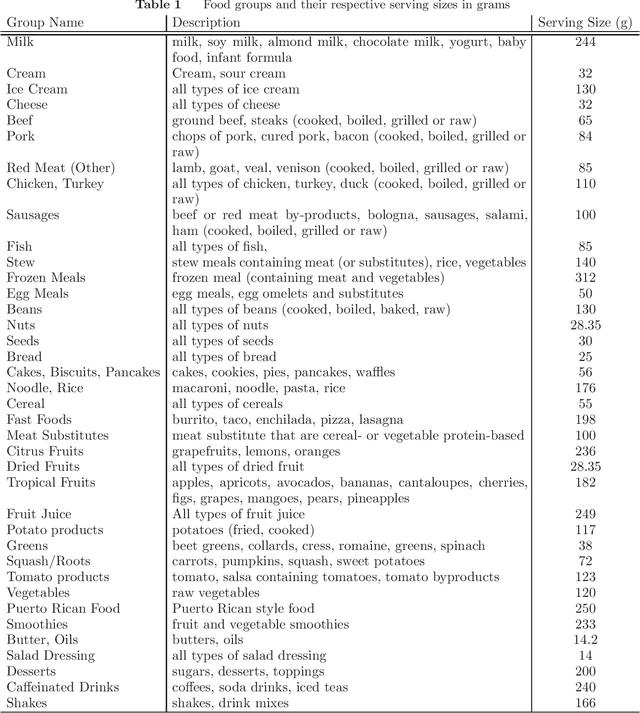
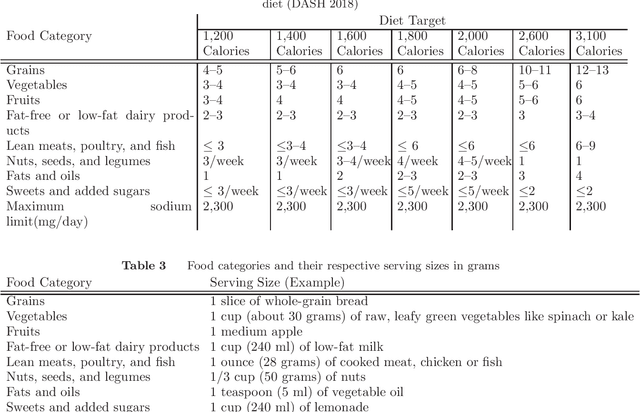
Linear constrained optimization techniques have been applied to many real-world settings. In recent years, inferring the unknown parameters and functions inside an optimization model has also gained traction. This inference is often based on existing observations and/or known parameters. Consequently, such models require reliable, easily accessed, and easily interpreted examples to be evaluated. To facilitate research in such directions, we provide a modified dataset based on dietary behaviors of different groups of people, their demographics, and pre-existing conditions, among other factors. This data is gathered from the National Health and Nutrition Examination Survey (NHANES) and complemented with the nutritional data from the United States Department of Agriculture (USDA). We additionally provide tailored datasets for hypertension and pre-diabetic patients as groups of interest who may benefit from targetted diets such as the Dietary Approaches to Stop Hypertension (DASH) eating plan. The data is compiled and curated in such a way that it is suitable as input to linear optimization models. We hope that this data and its supplementary, open-accessed materials can accelerate and simplify interpretations and research on linear optimization and constrained inference models. The complete dataset can be found in the following repository: https://github.com/CSSEHealthcare/InverseLearning
Artificial Intelligence-based Clinical Decision Support for COVID-19 -- Where Art Thou?
Jun 05, 2020The COVID-19 crisis has brought about new clinical questions, new workflows, and accelerated distributed healthcare needs. While artificial intelligence (AI)-based clinical decision support seemed to have matured, the application of AI-based tools for COVID-19 has been limited to date. In this perspective piece, we identify opportunities and requirements for AI-based clinical decision support systems and highlight challenges that impact "AI readiness" for rapidly emergent healthcare challenges.