 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmallPlan: Leverage Small Language Models for Sequential Path Planning with Simulation-Powered, LLM-Guided Distillation
May 01, 2025Efficient path planning in robotics, particularly within large-scale, dynamic environments, remains a significant hurdle. While Large Language Models (LLMs) offer strong reasoning capabilities, their high computational cost and limited adaptability in dynamic scenarios hinder real-time deployment on edge devices. We present SmallPlan -- a novel framework leveraging LLMs as teacher models to train lightweight Small Language Models (SLMs) for high-level path planning tasks. In SmallPlan, the SLMs provide optimal action sequences to navigate across scene graphs that compactly represent full-scaled 3D scenes. The SLMs are trained in a simulation-powered, interleaved manner with LLM-guided supervised fine-tuning (SFT) and reinforcement learning (RL). This strategy not only enables SLMs to successfully complete navigation tasks but also makes them aware of important factors like travel distance and number of trials. Through experiments, we demonstrate that the fine-tuned SLMs perform competitively with larger models like GPT-4o on sequential path planning, without suffering from hallucination and overfitting. SmallPlan is resource-efficient, making it well-suited for edge-device deployment and advancing practical autonomous robotics.
TESGNN: Temporal Equivariant Scene Graph Neural Networks for Efficient and Robust Multi-View 3D Scene Understanding
Nov 15, 2024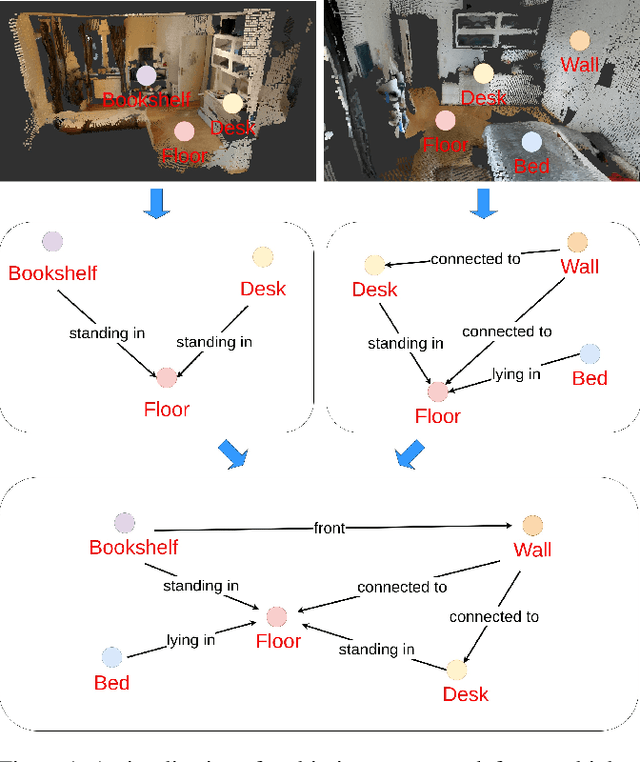



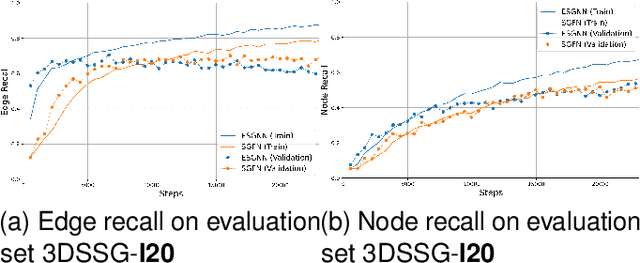
Scene graphs have proven to be highly effective for various scene understanding tasks due to their compact and explicit representation of relational information. However, current methods often overlook the critical importance of preserving symmetry when generating scene graphs from 3D point clouds, which can lead to reduced accuracy and robustness, particularly when dealing with noisy, multi-view data. This work, to the best of our knowledge, presents the first implementation of an Equivariant Scene Graph Neural Network (ESGNN) to generate semantic scene graphs from 3D point clouds, specifically for enhanced scene understanding. Furthermore, a significant limitation of prior methods is the absence of temporal modeling to capture time-dependent relationships among dynamically evolving entities within a scene. To address this gap, we introduce a novel temporal layer that leverages the symmetry-preserving properties of ESGNN to fuse scene graphs across multiple sequences into a unified global representation by an approximate graph-matching algorithm. Our combined architecture, termed the Temporal Equivariant Scene Graph Neural Network (TESGNN), not only surpasses existing state-of-the-art methods in scene estimation accuracy but also achieves faster convergence. Importantly, TESGNN is computationally efficient and straightforward to implement using existing frameworks, making it well-suited for real-time applications in robotics and computer vision. This approach paves the way for more robust and scalable solutions to complex multi-view scene understanding challenges. Our source code is publicly available at: https://github.com/HySonLab/TESGraph
ESGNN: Towards Equivariant Scene Graph Neural Network for 3D Scene Understanding
Jun 30, 2024

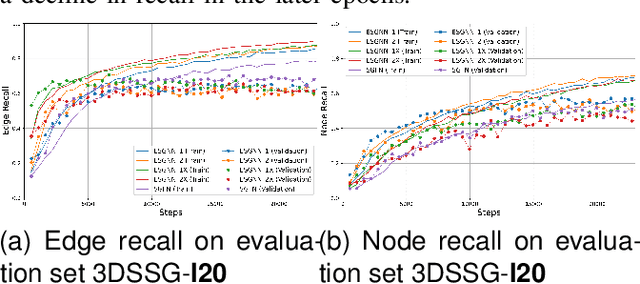
Scene graphs have been proven to be useful for various scene understanding tasks due to their compact and explicit nature. However, existing approaches often neglect the importance of maintaining the symmetry-preserving property when generating scene graphs from 3D point clouds. This oversight can diminish the accuracy and robustness of the resulting scene graphs, especially when handling noisy, multi-view 3D data. This work, to the best of our knowledge, is the first to implement an Equivariant Graph Neural Network in semantic scene graph generation from 3D point clouds for scene understanding. Our proposed method, ESGNN, outperforms existing state-of-the-art approaches, demonstrating a significant improvement in scene estimation with faster convergence. ESGNN demands low computational resources and is easy to implement from available frameworks, paving the way for real-time applications such as robotics and computer vision.