 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many radiographs are needed to re-train a deep learning system for object detection?
Oct 17, 2022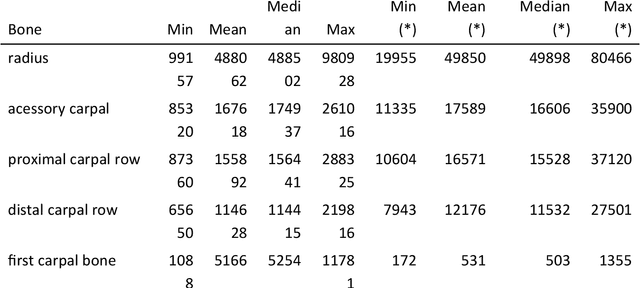

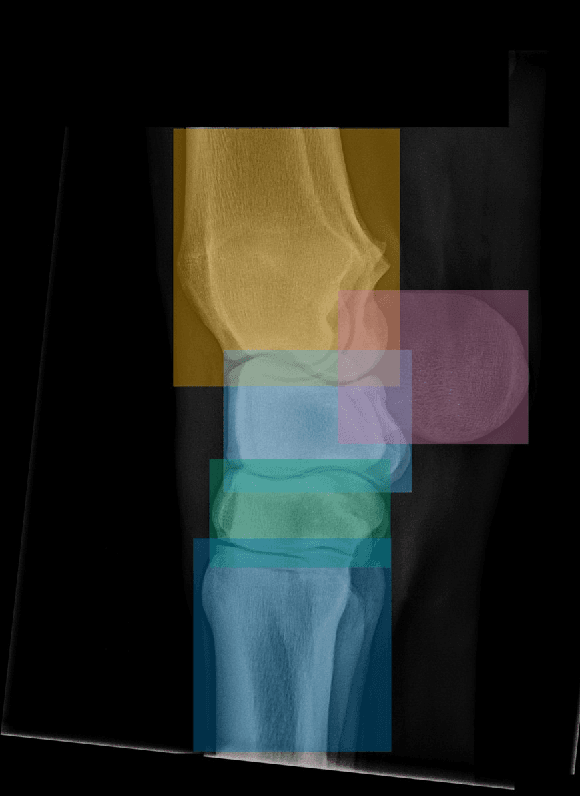
Background: Object detection in radiograph computer vision has largely benefited from progress in deep convolutional neural networks and can, for example, annotate a radiograph with a box around a knee joint or intervertebral disc. Is deep learning capable of detect small (less than 1% of the image) in radiographs? And how many radiographs do we need use when re-training a deep learning model? Methods: We annotated 396 radiographs of left and right carpi dorsal 75 medial to palmarolateral oblique (DMPLO) projection with the location of radius, proximal row of carpal bones, distal row of carpal bones, accessory carpal bone, first carpal bone (if present), and metacarpus (metacarpal II, III, and IV). The radiographs and respective annotations were splited into sets that were used to leave-one-out cross-validation of models created using transfer learn from YOLOv5s. Results: Models trained using 96 radiographs or more achieved precision, recall and mAP above 0.95, including for the first carpal bone, when trained for 32 epochs. The best model needed the double of epochs to learn to detect the first carpal bone compared with the other bones. Conclusions: Free and open source state of the art object detection models based on deep learning can be re-trained for radiograph computer vision applications with 100 radiographs and achieved precision, recall and mAP above 0.95.
Speech Forensics: Blind Voice Mimicry Detection
Sep 26, 2022



Audio is one of the most used way of human communication, but at the same time it can be easily misused by to trick people. With the revolution of AI, the related technologies are now accessible to almost everyone thus making it simple for the criminals to commit crimes and forgeries. In this work, we introduce a deep learning method to develop a classifier that will blindly classify an input audio as real or mimicked. The proposed model was trained on a set of important features extracted from a large dataset of audios to get a classifier that was tested on the same set of features from different audios. Two datasets were created for this work; an all English data set and a mixed data set (Arabic and English). These datasets have been made available through GitHub for the use of the research community at https://github.com/SaSs7/Dataset. For the purpose of comparison, the audios were also classified through human inspection with the subjects being the native speakers. The ensued results were interesting and exhibited formidable accuracy.
Seamless Copy Move Manipulation in Digital Images
Oct 12, 2021
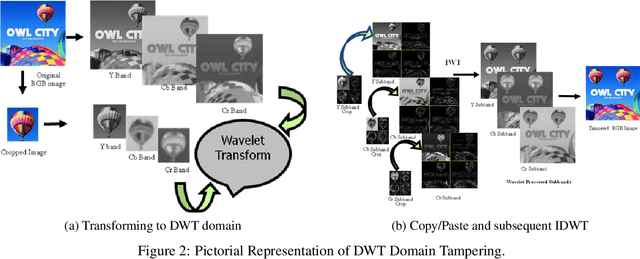


The importance and relevance of digital image forensics has attracted researchers to establish different techniques for creating as well as detecting forgeries. The core category in passive image forgery is copy-move image forgery that affects the originality of image by applying a different transformation. In this paper frequency domain image manipulation method is being presented.The method exploits the localized nature of discrete wavelet transform (DWT) to get hold of the region of the host image to be manipulated. Both the patch and host image are subjected to DWT at the same level $l$ to get $3l + 1$ sub-bands and each sub-band of the patch is pasted to the identified region in the corresponding sub-band of the host image. The resultant manipulated host sub-bands are then subjected to inverse DWT to get the final manipulated host image. The proposed method shows good resistance against detection by two frequency domain forgery detection methods from the literature. The purpose of this research work is to create the forgery and highlight the need to produce forgery detection methods that are robust against the malicious copy-move forgery.
Super-Resolution via Deep Learning
Jun 28, 2017



The recent phenomenal interest in convolutional neural networks (CNNs) must have made it inevitable for the super-resolution (SR) community to explore its potential. The response has been immense and in the last three years, since the advent of the pioneering work, there appeared too many works not to warrant a comprehensive survey. This paper surveys the SR literature in the context of deep learning. We focus on the three important aspects of multimedia - namely image, video and multi-dimensions, especially depth maps. In each case, first relevant benchmarks are introduced in the form of datasets and state of the art SR methods, excluding deep learning. Next is a detailed analysis of the individual works, each including a short description of the method and a critique of the results with special reference to the benchmarking done. This is followed by minimum overall benchmarking in the form of comparison on some common dataset, while relying on the results reported in various works.