 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many radiographs are needed to re-train a deep learning system for object detection?
Paper and Code
Oct 17, 2022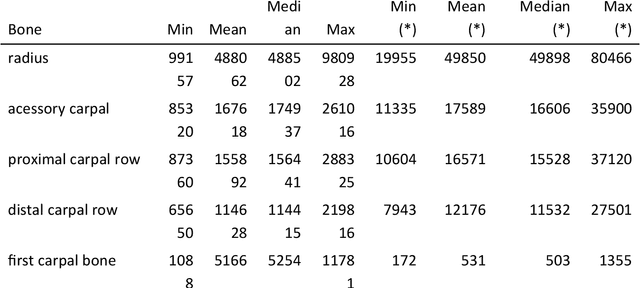

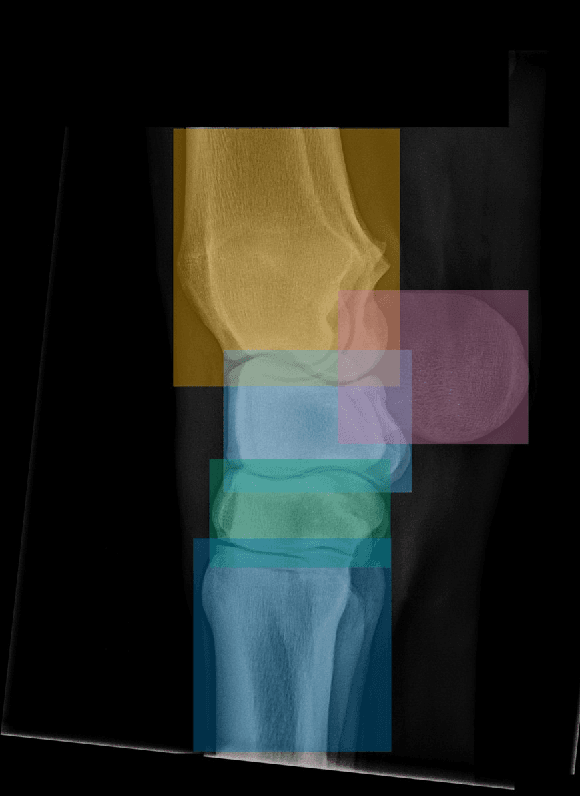
Background: Object detection in radiograph computer vision has largely benefited from progress in deep convolutional neural networks and can, for example, annotate a radiograph with a box around a knee joint or intervertebral disc. Is deep learning capable of detect small (less than 1% of the image) in radiographs? And how many radiographs do we need use when re-training a deep learning model? Methods: We annotated 396 radiographs of left and right carpi dorsal 75 medial to palmarolateral oblique (DMPLO) projection with the location of radius, proximal row of carpal bones, distal row of carpal bones, accessory carpal bone, first carpal bone (if present), and metacarpus (metacarpal II, III, and IV). The radiographs and respective annotations were splited into sets that were used to leave-one-out cross-validation of models created using transfer learn from YOLOv5s. Results: Models trained using 96 radiographs or more achieved precision, recall and mAP above 0.95, including for the first carpal bone, when trained for 32 epochs. The best model needed the double of epochs to learn to detect the first carpal bone compared with the other bones. Conclusions: Free and open source state of the art object detection models based on deep learning can be re-trained for radiograph computer vision applications with 100 radiographs and achieved precision, recall and mAP above 0.95.