 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Multi-View Classification of Features
Aug 02, 2021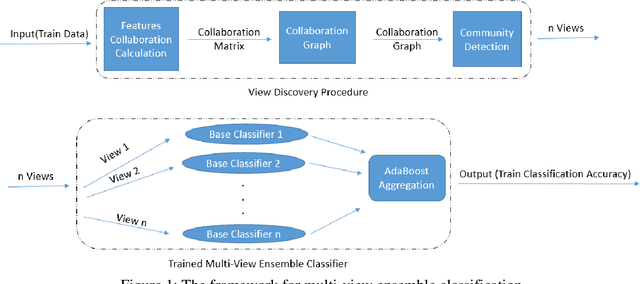

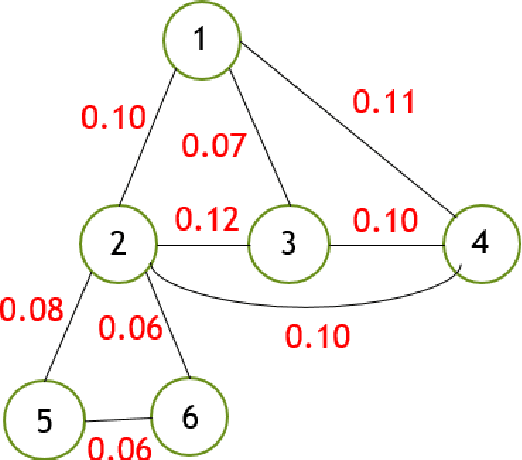
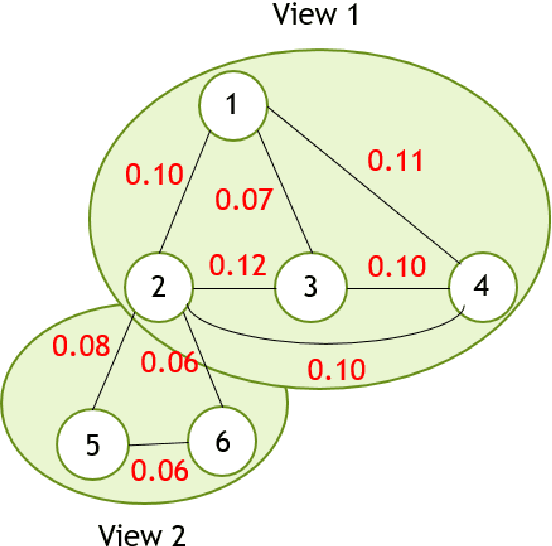
One of the most important problems in the field of pattern recognition is data classification. Due to the increasing development of technologies introduced in the field of data classification, some of the solutions are still open and need more research. One of the challenging problems in this area is the curse of dimensionality of the feature set of the data classification problem. In solving the data classification problems, when the feature set is too large, typical approaches will not be able to solve the problem. In this case, an approach can be used to partition the feature set into multiple feature sub-sets so that the data classification problem is solved for each of the feature subsets and finally using the ensemble classification, the classification is applied to the entire feature set. In the above-mentioned approach, the partitioning of feature set into feature sub-sets is still an interesting area in the literature of this field. In this research, an innovative framework for multi-view ensemble classification, inspired by the problem of object recognition in the multiple views theory of humans, is proposed. In this method, at first, the collaboration values between the features is calculated using a criterion called the features collaboration criterion. Then, the collaboration graph is formed based on the calculated collaboration values. In the next step, using the community detection method, graph communities are found. The communities are considered as the problem views and the different base classifiers are trained for different views using the views corresponding training data. The multi-view ensemble classifier is then formed by a combination of base classifiers based on the AdaBoost algorithm. The simulation results of the proposed method on the real and synthetic datasets show that the proposed method increases the classification accuracy.
Crossbreeding in Random Forest
Jan 21, 2021



Ensemble learning methods are designed to benefit from multiple learning algorithms for better predictive performance. The tradeoff of this improved performance is slower speed and larger size of ensemble learning systems compared to single learning systems. In this paper, we present a novel approach to deal with this problem in Random Forest (RF) as one of the most powerful ensemble methods. The method is based on crossbreeding of the best tree branches to increase the performance of RF in space and speed while keeping the performance in the classification measures. The proposed approach has been tested on a group of synthetic and real datasets and compared to the standard RF approach. Several evaluations have been conducted to determine the effects of the Crossbred RF (CRF) on the accuracy and the number of trees in a forest. The results show better performance of CRF compared to RF.