 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming an image through the eye: The retina seen as a dithered scalable image coder
Feb 10, 2012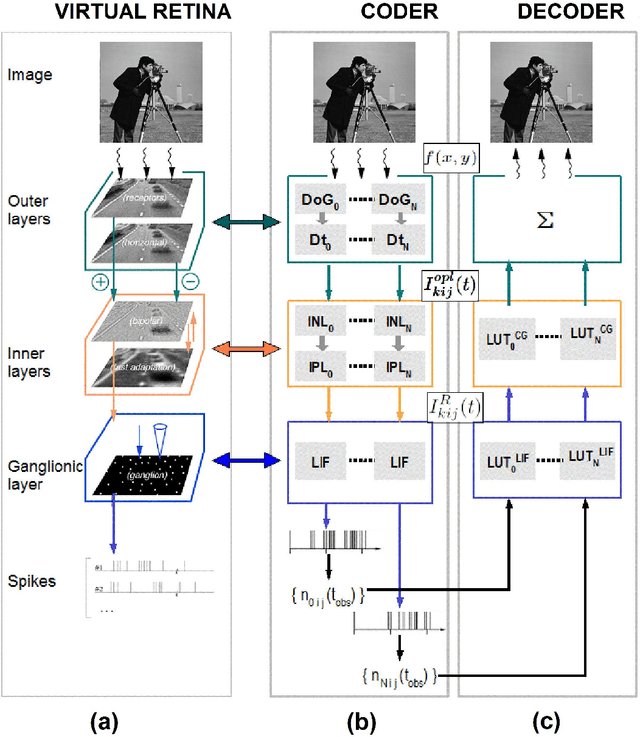

We propose the design of an original scalable image coder/decoder that is inspired from the mammalians retina. Our coder accounts for the time-dependent and also nondeterministic behavior of the actual retina. The present work brings two main contributions: As a first step, (i) we design a deterministic image coder mimicking most of the retinal processing stages and then (ii) we introduce a retinal noise in the coding process, that we model here as a dither signal, to gain interesting perceptual features. Regarding our first contribution, our main source of inspiration will be the biologically plausible model of the retina called Virtual Retina. The main novelty of this coder is to show that the time-dependent behavior of the retina cells could ensure, in an implicit way, scalability and bit allocation. Regarding our second contribution, we reconsider the inner layers of the retina. We emit a possible interpretation for the non-determinism observed by neurophysiologists in their output. For this sake, we model the retinal noise that occurs in these layers by a dither signal. The dithering process that we propose adds several interesting features to our image coder. The dither noise whitens the reconstruction error and decorrelates it from the input stimuli. Furthermore, integrating the dither noise in our coder allows a faster recognition of the fine details of the image during the decoding process. Our present paper goal is twofold. First, we aim at mimicking as closely as possible the retina for the design of a novel image coder while keeping encouraging performances. Second, we bring a new insight concerning the non-deterministic behavior of the retina.
A bio-inspired image coder with temporal scalability
Dec 22, 2011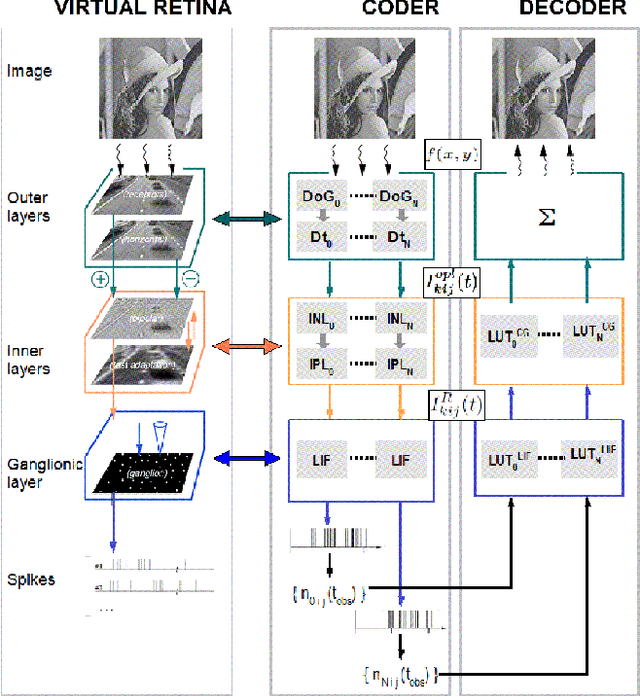
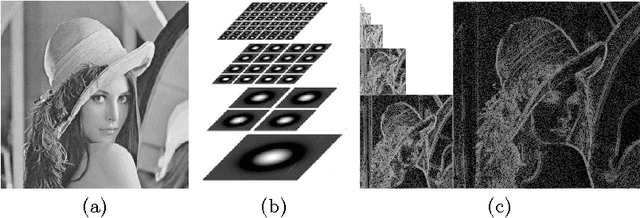
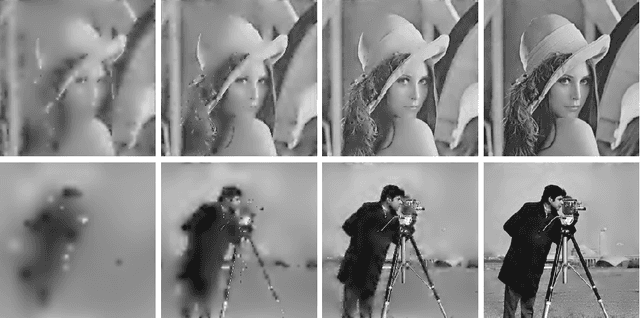
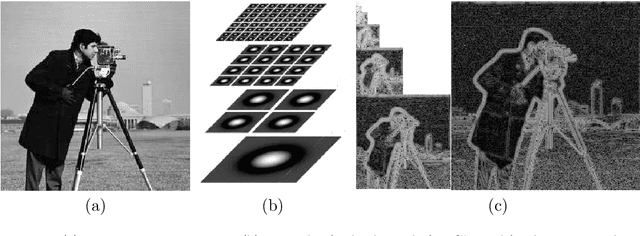
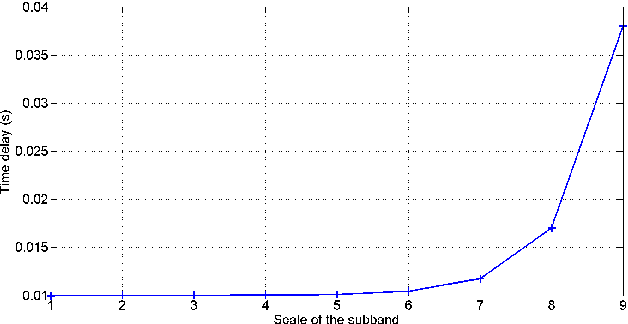
We present a novel bio-inspired and dynamic coding scheme for static images. Our coder aims at reproducing the main steps of the visual stimulus processing in the mammalian retina taking into account its time behavior. The main novelty of this work is to show how to exploit the time behavior of the retina cells to ensure, in a simple way, scalability and bit allocation. To do so, our main source of inspiration will be the biologically plausible retina model called Virtual Retina. Following a similar structure, our model has two stages. The first stage is an image transform which is performed by the outer layers in the retina. Here it is modelled by filtering the image with a bank of difference of Gaussians with time-delays. The second stage is a time-dependent analog-to-digital conversion which is performed by the inner layers in the retina. Thanks to its conception, our coder enables scalability and bit allocation across time. Also, our decoded images do not show annoying artefacts such as ringing and block effects. As a whole, this article shows how to capture the main properties of a biological system, here the retina, in order to design a new efficient coder.
Exact Reconstruction of the Rank Order Coding using Frames Theory
Jul 01, 2011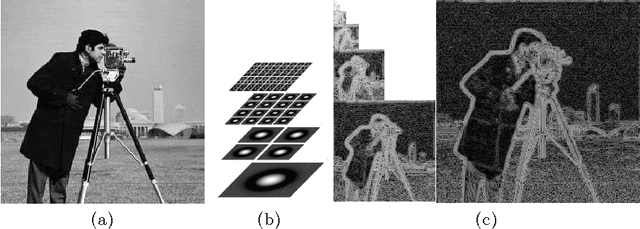


Our goal is to revisit rank order coding by proposing an original exact decoding procedure for it. Rank order coding was proposed by Simon Thorpe et al. who stated that the retina represents the visual stimulus by the order in which its cells are activated. A classical rank order coder/decoder was then designed on this basis [1]. Though, it appeared that the decoding procedure employed yields reconstruction errors that limit the model Rate/Quality performances when used as an image codec. The attempts made in the literature to overcome this issue are time consuming and alter the coding procedure, or are lacking mathematical support and feasibility for standard size images. Here we solve this problem in an original fashion by using the frames theory, where a frame of a vector space designates an extension for the notion of basis. First, we prove that the analyzing filter bank considered is a frame, and then we define the corresponding dual frame that is necessary for the exact image reconstruction. Second, to deal with the problem of memory overhead, we design a recursive out-of-core blockwise algorithm for the computation of this dual frame. Our work provides a mathematical formalism for the retinal model under study and defines a simple and exact reverse transform for it with up to 270 dB of PSNR gain compared to [1]. Furthermore, the framework presented here can be extended to several models of the visual cortical areas using redundant representations.