 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality versus uniformity in deep neural networks
Apr 10, 2023Deep feedforward networks initialized along the edge of chaos exhibit exponentially superior training ability as quantified by maximum trainable depth. In this work, we explore the effect of saturation of the tanh activation function along the edge of chaos. In particular, we determine the line of uniformity in phase space along which the post-activation distribution has maximum entropy. This line intersects the edge of chaos, and indicates the regime beyond which saturation of the activation function begins to impede training efficiency. Our results suggest that initialization along the edge of chaos is a necessary but not sufficient condition for optimal trainability.
The edge of chaos: quantum field theory and deep neural networks
Sep 27, 2021


We explicitly construct the quantum field theory corresponding to a general class of deep neural networks encompassing both recurrent and feedforward architectures. We first consider the mean-field theory (MFT) obtained as the leading saddlepoint in the action, and derive the condition for criticality via the largest Lyapunov exponent. We then compute the loop corrections to the correlation function in a perturbative expansion in the ratio of depth $T$ to width $N$, and find a precise analogy with the well-studied $O(N)$ vector model, in which the variance of the weight initializations plays the role of the 't Hooft coupling. In particular, we compute both the $\mathcal{O}(1)$ corrections quantifying fluctuations from typicality in the ensemble of networks, and the subleading $\mathcal{O}(T/N)$ corrections due to finite-width effects. These provide corrections to the correlation length that controls the depth to which information can propagate through the network, and thereby sets the scale at which such networks are trainable by gradient descent. Our analysis provides a first-principles approach to the rapidly emerging NN-QFT correspondence, and opens several interesting avenues to the study of criticality in deep neural networks.
Towards quantifying information flows: relative entropy in deep neural networks and the renormalization group
Jul 14, 2021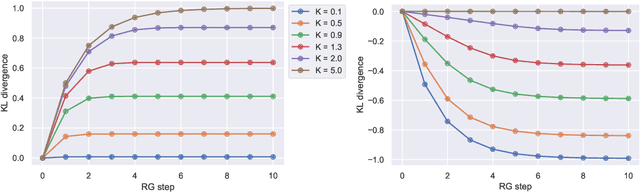
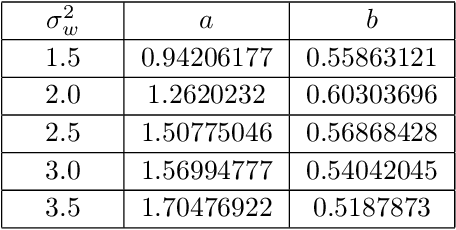
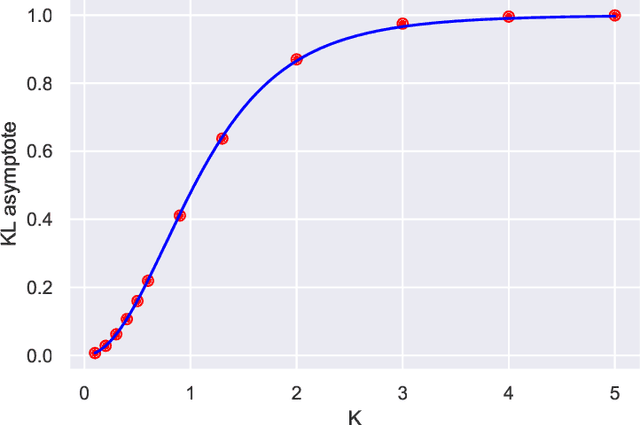

We investigate the analogy between the renormalization group (RG) and deep neural networks, wherein subsequent layers of neurons are analogous to successive steps along the RG. In particular, we quantify the flow of information by explicitly computing the relative entropy or Kullback-Leibler divergence in both the one- and two-dimensional Ising models under decimation RG, as well as in a feedforward neural network as a function of depth. We observe qualitatively identical behavior characterized by the monotonic increase to a parameter-dependent asymptotic value. On the quantum field theory side, the monotonic increase confirms the connection between the relative entropy and the c-theorem. For the neural networks, the asymptotic behavior may have implications for various information maximization methods in machine learning, as well as for disentangling compactness and generalizability. Furthermore, while both the two-dimensional Ising model and the random neural networks we consider exhibit non-trivial critical points, the relative entropy appears insensitive to the phase structure of either system. In this sense, more refined probes are required in order to fully elucidate the flow of information in these models.