 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying BioBERT to Extract Germline Gene-Disease Associations for Building a Knowledge Graph from the Biomedical Literature
Sep 30, 2023Published biomedical information has and continues to rapidly increase. The recent advancements in Natural Language Processing (NLP), have generated considerable interest in automating the extraction, normalization, and representation of biomedical knowledge about entities such as genes and diseases. Our study analyzes germline abstracts in the construction of knowledge graphs of the of the immense work that has been done in this area for genes and diseases. This paper presents SimpleGermKG, an automatic knowledge graph construction approach that connects germline genes and diseases. For the extraction of genes and diseases, we employ BioBERT, a pre-trained BERT model on biomedical corpora. We propose an ontology-based and rule-based algorithm to standardize and disambiguate medical terms. For semantic relationships between articles, genes, and diseases, we implemented a part-whole relation approach to connect each entity with its data source and visualize them in a graph-based knowledge representation. Lastly, we discuss the knowledge graph applications, limitations, and challenges to inspire the future research of germline corpora. Our knowledge graph contains 297 genes, 130 diseases, and 46,747 triples. Graph-based visualizations are used to show the results.
* 10 pages
Semi-Automating Knowledge Base Construction for Cancer Genetics
May 26, 2020
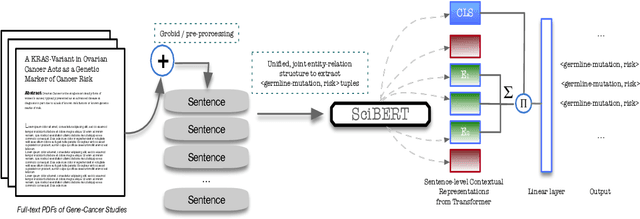
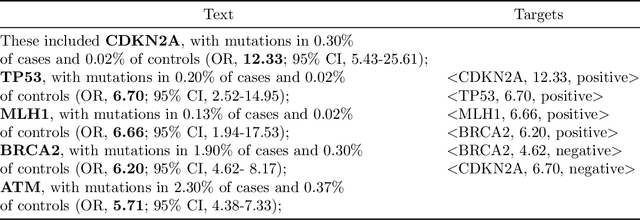

In this work, we consider the exponentially growing subarea of genetics in cancer. The need to synthesize and centralize this evidence for dissemination has motivated a team of physicians to manually construct and maintain a knowledge base that distills key results reported in the literature. This is a laborious process that entails reading through full-text articles to understand the study design, assess study quality, and extract the reported cancer risk estimates associated with particular hereditary cancer genes (i.e., penetrance). In this work, we propose models to automatically surface key elements from full-text cancer genetics articles, with the ultimate aim of expediting the manual workflow currently in place. We propose two challenging tasks that are critical for characterizing the findings reported cancer genetics studies: (i) Extracting snippets of text that describe \emph{ascertainment mechanisms}, which in turn inform whether the population studied may introduce bias owing to deviations from the target population; (ii) Extracting reported risk estimates (e.g., odds or hazard ratios) associated with specific germline mutations. The latter task may be viewed as a joint entity tagging and relation extraction problem. To train models for these tasks, we induce distant supervision over tokens and snippets in full-text articles using the manually constructed knowledge base. We propose and evaluate several model variants, including a transformer-based joint entity and relation extraction model to extract <germline mutation, risk-estimate>} pairs. We observe strong empirical performance, highlighting the practical potential for such models to aid KB construction in this space. We ablate components of our model, observing, e.g., that a joint model for <germline mutation, risk-estimate> fares substantially better than a pipelined approach.