 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Vision-Language Models in Remote Sensing without Human Annotations
Sep 11, 2024The prominence of generalized foundation models in vision-language integration has witnessed a surge, given their multifarious applications. Within the natural domain, the procurement of vision-language datasets to construct these foundation models is facilitated by their abundant availability and the ease of web crawling. Conversely, in the remote sensing domain, although vision-language datasets exist, their volume is suboptimal for constructing robust foundation models. This study introduces an approach to curate vision-language datasets by employing an image decoding machine learning model, negating the need for human-annotated labels. Utilizing this methodology, we amassed approximately 9.6 million vision-language paired datasets in VHR imagery. The resultant model outperformed counterparts that did not leverage publicly available vision-language datasets, particularly in downstream tasks such as zero-shot classification, semantic localization, and image-text retrieval. Moreover, in tasks exclusively employing vision encoders, such as linear probing and k-NN classification, our model demonstrated superior efficacy compared to those relying on domain-specific vision-language datasets.
On Pitfalls of $\textit{RemOve-And-Retrain}$: Data Processing Inequality Perspective
May 11, 2023Approaches for appraising feature importance approximations, alternatively referred to as attribution methods, have been established across an extensive array of contexts. The development of resilient techniques for performance benchmarking constitutes a critical concern in the sphere of explainable deep learning. This study scrutinizes the dependability of the RemOve-And-Retrain (ROAR) procedure, which is prevalently employed for gauging the performance of feature importance estimates. The insights gleaned from our theoretical foundation and empirical investigations reveal that attributions containing lesser information about the decision function may yield superior results in ROAR benchmarks, contradicting the original intent of ROAR. This occurrence is similarly observed in the recently introduced variant RemOve-And-Debias (ROAD), and we posit a persistent pattern of blurriness bias in ROAR attribution metrics. Our findings serve as a warning against indiscriminate use on ROAR metrics. The code is available as open source.
A Billion-scale Foundation Model for Remote Sensing Images
Apr 11, 2023



As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
Contrastive Multiview Coding with Electro-optics for SAR Semantic Segmentation
Aug 31, 2021
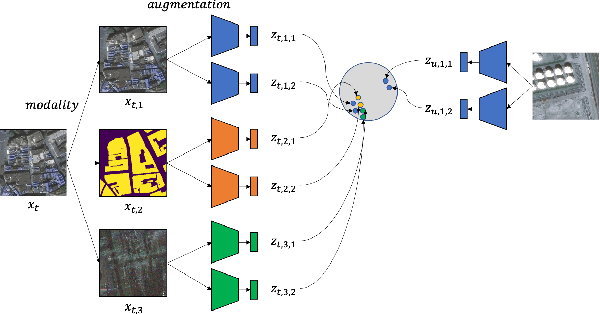
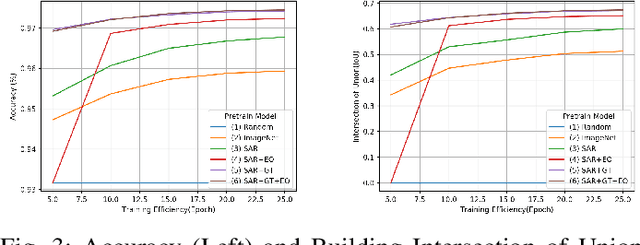
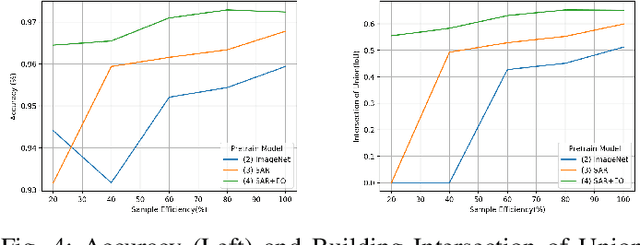
In the training of deep learning models, how the model parameters are initialized greatly affects the model performance, sample efficiency, and convergence speed. Representation learning for model initialization has recently been actively studied in the remote sensing field. In particular, the appearance characteristics of the imagery obtained using the a synthetic aperture radar (SAR) sensor are quite different from those of general electro-optical (EO) images, and thus representation learning is even more important in remote sensing domain. Motivated from contrastive multiview coding, we propose multi-modal representation learning for SAR semantic segmentation. Unlike previous studies, our method jointly uses EO imagery, SAR imagery, and a label mask. Several experiments show that our approach is superior to the existing methods in model performance, sample efficiency, and convergence speed.