 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Multiview Coding with Electro-optics for SAR Semantic Segmentation
Paper and Code
Aug 31, 2021
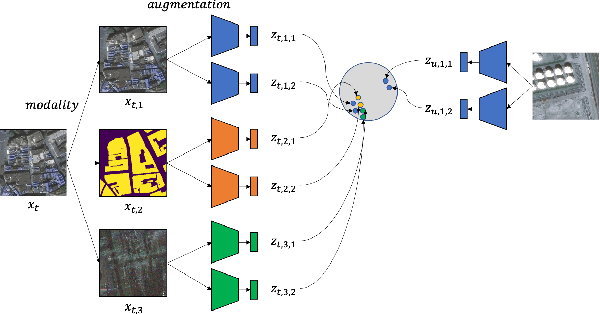
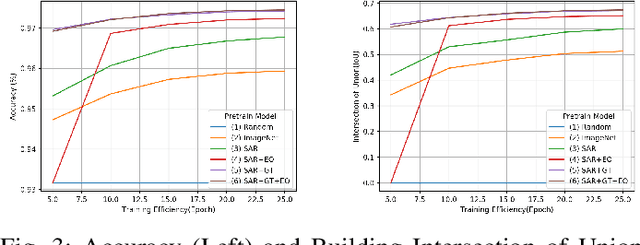
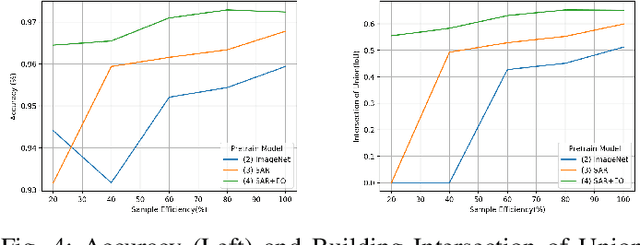
In the training of deep learning models, how the model parameters are initialized greatly affects the model performance, sample efficiency, and convergence speed. Representation learning for model initialization has recently been actively studied in the remote sensing field. In particular, the appearance characteristics of the imagery obtained using the a synthetic aperture radar (SAR) sensor are quite different from those of general electro-optical (EO) images, and thus representation learning is even more important in remote sensing domain. Motivated from contrastive multiview coding, we propose multi-modal representation learning for SAR semantic segmentation. Unlike previous studies, our method jointly uses EO imagery, SAR imagery, and a label mask. Several experiments show that our approach is superior to the existing methods in model performance, sample efficiency, and convergence speed.