 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Data Augmentation with Preserving Foreground Regions in Medical Image Segmentation
Apr 26, 2023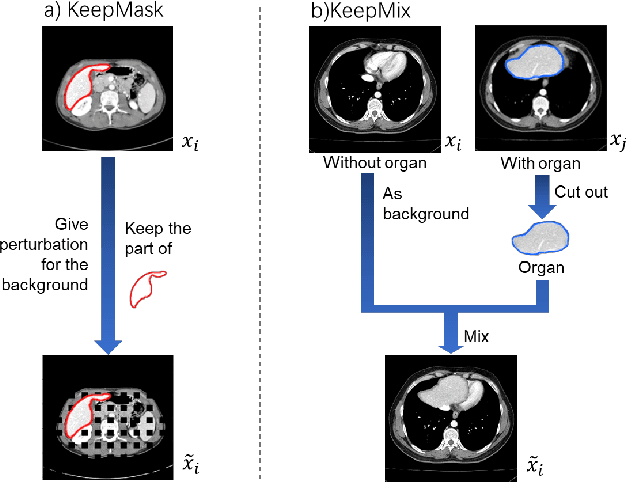
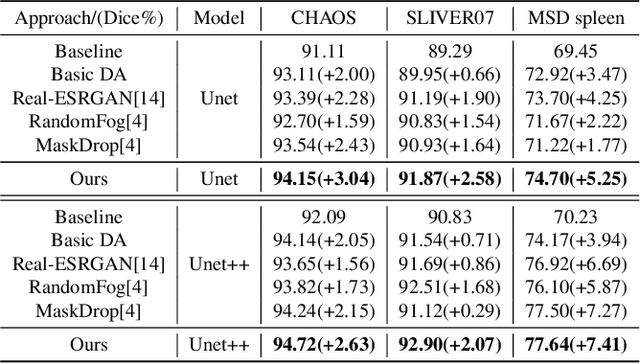
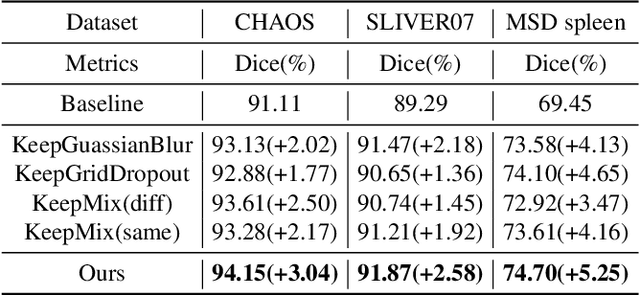
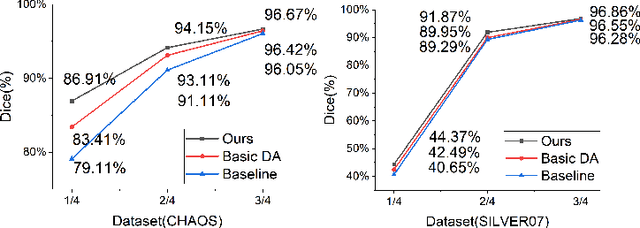
The development of medical image segmentation using deep learning can significantly support doctors' diagnoses. Deep learning needs large amounts of data for training, which also requires data augmentation to extend diversity for preventing overfitting. However, the existing methods for data augmentation of medical image segmentation are mainly based on models which need to update parameters and cost extra computing resources. We proposed data augmentation methods designed to train a high accuracy deep learning network for medical image segmentation. The proposed data augmentation approaches are called KeepMask and KeepMix, which can create medical images by better identifying the boundary of the organ with no more parameters. Our methods achieved better performance and obtained more precise boundaries for medical image segmentation on datasets. The dice coefficient of our methods achieved 94.15% (3.04% higher than baseline) on CHAOS and 74.70% (5.25% higher than baseline) on MSD spleen with Unet.
Abstract Generation based on Rhetorical Structure Extraction
Nov 17, 1994
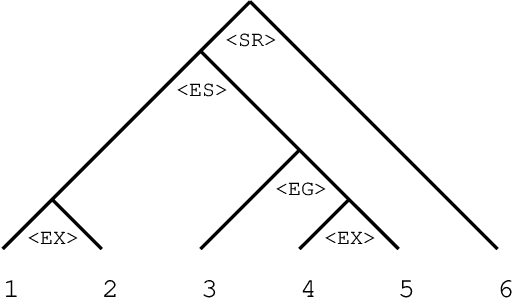
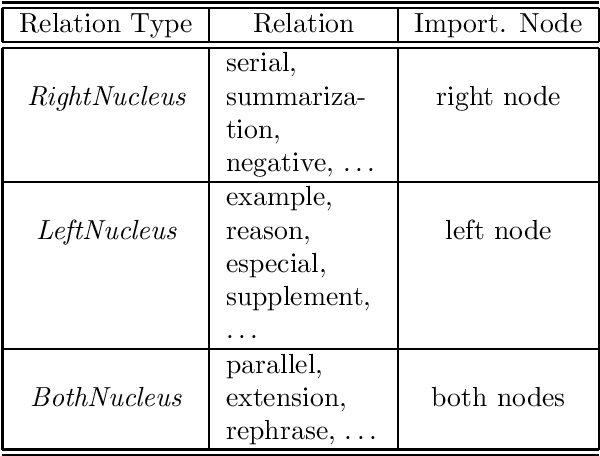
We have developed an automatic abstract generation system for Japanese expository writings based on rhetorical structure extraction. The system first extracts the rhetorical structure, the compound of the rhetorical relations between sentences, and then cuts out less important parts in the extracted structure to generate an abstract of the desired length. Evaluation of the generated abstract showed that it contains at maximum 74\% of the most important sentences of the original text. The system is now utilized as a text browser for a prototypical interactive document retrieval system.