 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign or Not-Benign Overfitting in Token Selection of Attention Mechanism
Sep 26, 2024



Modern over-parameterized neural networks can be trained to fit the training data perfectly while still maintaining a high generalization performance. This "benign overfitting" phenomenon has been studied in a surge of recent theoretical work; however, most of these studies have been limited to linear models or two-layer neural networks. In this work, we analyze benign overfitting in the token selection mechanism of the attention architecture, which characterizes the success of transformer models. We first show the existence of a benign overfitting solution and explain its mechanism in the attention architecture. Next, we discuss whether the model converges to such a solution, raising the difficulties specific to the attention architecture. We then present benign overfitting cases and not-benign overfitting cases by conditioning different scenarios based on the behavior of attention probabilities during training. To the best of our knowledge, this is the first study to characterize benign overfitting for the attention mechanism.
End-to-End Training Induces Information Bottleneck through Layer-Role Differentiation: A Comparative Analysis with Layer-wise Training
Feb 14, 2024End-to-end (E2E) training, optimizing the entire model through error backpropagation, fundamentally supports the advancements of deep learning. Despite its high performance, E2E training faces the problems of memory consumption, parallel computing, and discrepancy with the functionalities of the actual brain. Various alternative methods have been proposed to overcome these difficulties; however, no one can yet match the performance of E2E training, thereby falling short in practicality. Furthermore, there is no deep understanding regarding differences in the trained model properties beyond the performance gap. In this paper, we reconsider why E2E training demonstrates a superior performance through a comparison with layer-wise training, a non-E2E method that locally sets errors. On the basis of the observation that E2E training has an advantage in propagating input information, we analyze the information plane dynamics of intermediate representations based on the Hilbert-Schmidt independence criterion (HSIC). The results of our normalized HSIC value analysis reveal the E2E training ability to exhibit different information dynamics across layers, in addition to efficient information propagation. Furthermore, we show that this layer-role differentiation leads to the final representation following the information bottleneck principle. It suggests the need to consider the cooperative interactions between layers, not just the final layer when analyzing the information bottleneck of deep learning.
Analyzing Lottery Ticket Hypothesis from PAC-Bayesian Theory Perspective
May 15, 2022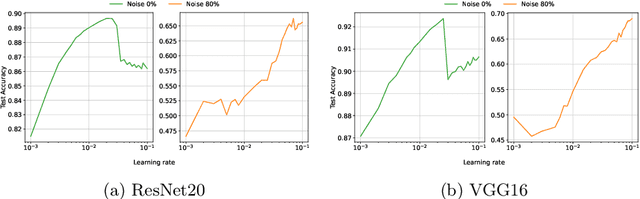
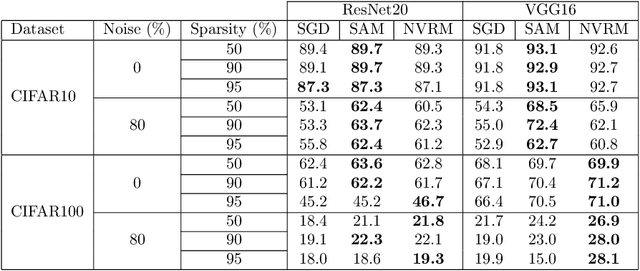
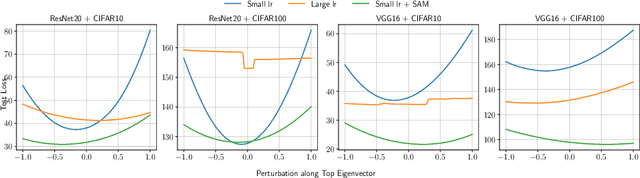

The lottery ticket hypothesis (LTH) has attracted attention because it can explain why over-parameterized models often show high generalization ability. It is known that when we use iterative magnitude pruning (IMP), which is an algorithm to find sparse networks with high generalization ability that can be trained from the initial weights independently, called winning tickets, the initial large learning rate does not work well in deep neural networks such as ResNet. However, since the initial large learning rate generally helps the optimizer to converge to flatter minima, we hypothesize that the winning tickets have relatively sharp minima, which is considered a disadvantage in terms of generalization ability. In this paper, we confirm this hypothesis and show that the PAC-Bayesian theory can provide an explicit understanding of the relationship between LTH and generalization behavior. On the basis of our experimental findings that flatness is useful for improving accuracy and robustness to label noise and that the distance from the initial weights is deeply involved in winning tickets, we offer the PAC-Bayes bound using a spike-and-slab distribution to analyze winning tickets. Finally, we revisit existing algorithms for finding winning tickets from a PAC-Bayesian perspective and provide new insights into these methods.