 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Span Log-Linear Model and Fast Learning Algorithm
Feb 17, 2022
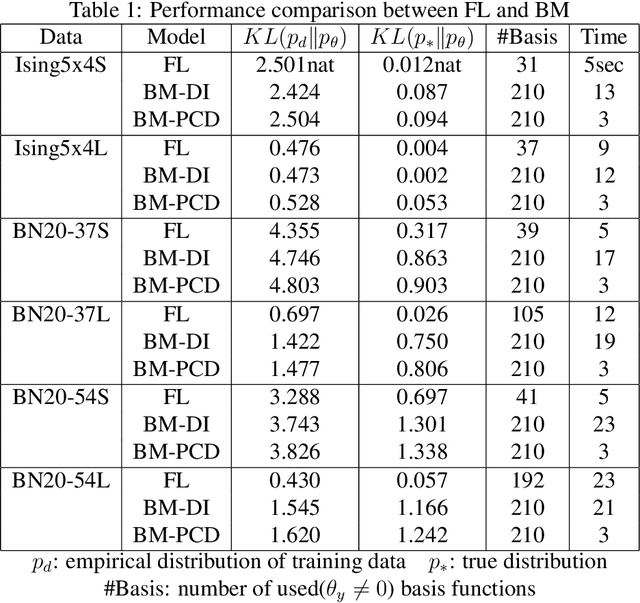


The full-span log-linear(FSLL) model introduced in this paper is considered an $n$-th order Boltzmann machine, where $n$ is the number of all variables in the target system. Let $X=(X_0,...,X_{n-1})$ be finite discrete random variables that can take $|X|=|X_0|...|X_{n-1}|$ different values. The FSLL model has $|X|-1$ parameters and can represent arbitrary positive distributions of $X$. The FSLL model is a "highest-order" Boltzmann machine; nevertheless, we can compute the dual parameters of the model distribution, which plays important roles in exponential families, in $O(|X|\log|X|)$ time. Furthermore, using properties of the dual parameters of the FSLL model, we can construct an efficient learning algorithm. The FSLL model is limited to small probabilistic models up to $|X|\approx2^{25}$; however, in this problem domain, the FSLL model flexibly fits various true distributions underlying the training data without any hyperparameter tuning. The experiments presented that the FSLL successfully learned six training datasets such that $|X|=2^{20}$ within one minute with a laptop PC.
Reconsidering Dependency Networks from an Information Geometry Perspective
Jul 02, 2021
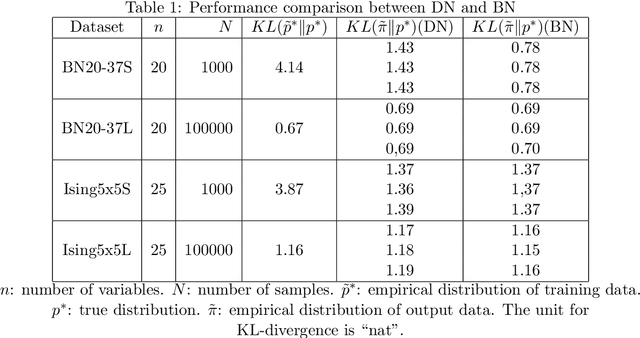
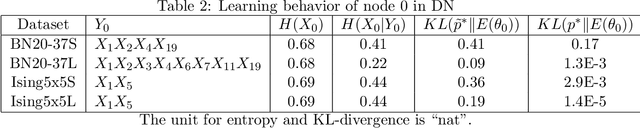
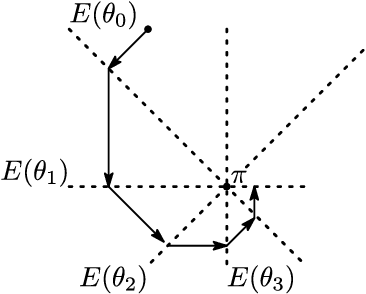
Dependency networks (Heckerman et al., 2000) are potential probabilistic graphical models for systems comprising a large number of variables. Like Bayesian networks, the structure of a dependency network is represented by a directed graph, and each node has a conditional probability table. Learning and inference are realized locally on individual nodes; therefore, computation remains tractable even with a large number of variables. However, the dependency network's learned distribution is the stationary distribution of a Markov chain called pseudo-Gibbs sampling and has no closed-form expressions. This technical disadvantage has impeded the development of dependency networks. In this paper, we consider a certain manifold for each node. Then, we can interpret pseudo-Gibbs sampling as iterative m-projections onto these manifolds. This interpretation provides a theoretical bound for the location where the stationary distribution of pseudo-Gibbs sampling exists in distribution space. Furthermore, this interpretation involves structure and parameter learning algorithms as optimization problems. In addition, we compare dependency and Bayesian networks experimentally. The results demonstrate that the dependency network and the Bayesian network have roughly the same performance in terms of the accuracy of their learned distributions. The results also show that the dependency network can learn much faster than the Bayesian network.
Constraint-free Graphical Model with Fast Learning Algorithm
Jun 17, 2012
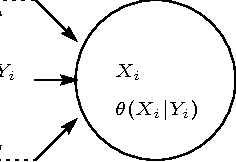
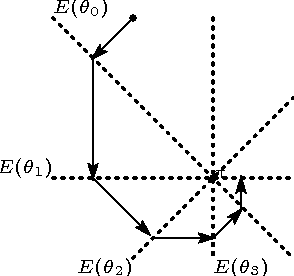
In this paper, we propose a simple, versatile model for learning the structure and parameters of multivariate distributions from a data set. Learning a Markov network from a given data set is not a simple problem, because Markov networks rigorously represent Markov properties, and this rigor imposes complex constraints on the design of the networks. Our proposed model removes these constraints, acquiring important aspects from the information geometry. The proposed parameter- and structure-learning algorithms are simple to execute as they are based solely on local computation at each node. Experiments demonstrate that our algorithms work appropriately.