 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic recognition of element classes and boundaries in the birdsong with variable sequences
Jan 23, 2016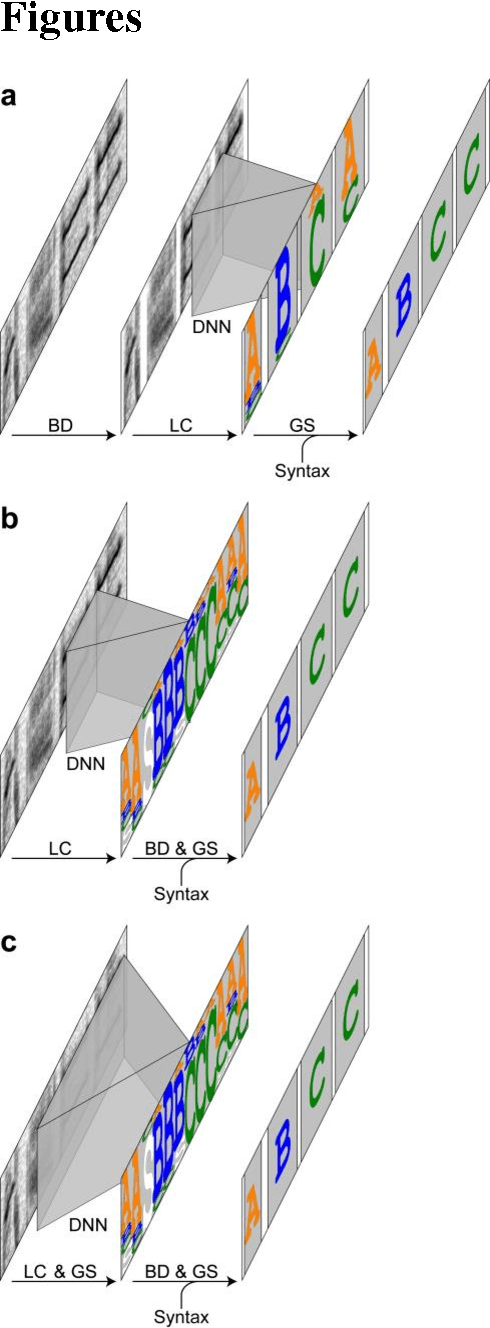



Researches on sequential vocalization often require analysis of vocalizations in long continuous sounds. In such studies as developmental ones or studies across generations in which days or months of vocalizations must be analyzed, methods for automatic recognition would be strongly desired. Although methods for automatic speech recognition for application purposes have been intensively studied, blindly applying them for biological purposes may not be an optimal solution. This is because, unlike human speech recognition, analysis of sequential vocalizations often requires accurate extraction of timing information. In the present study we propose automated systems suitable for recognizing birdsong, one of the most intensively investigated sequential vocalizations, focusing on the three properties of the birdsong. First, a song is a sequence of vocal elements, called notes, which can be grouped into categories. Second, temporal structure of birdsong is precisely controlled, meaning that temporal information is important in song analysis. Finally, notes are produced according to certain probabilistic rules, which may facilitate the accurate song recognition. We divided the procedure of song recognition into three sub-steps: local classification, boundary detection, and global sequencing, each of which corresponds to each of the three properties of birdsong. We compared the performances of several different ways to arrange these three steps. As results, we demonstrated a hybrid model of a deep neural network and a hidden Markov model is effective in recognizing birdsong with variable note sequences. We propose suitable arrangements of methods according to whether accurate boundary detection is needed. Also we designed the new measure to jointly evaluate the accuracy of note classification and boundary detection. Our methods should be applicable, with small modification and tuning, to the songs in other species that hold the three properties of the sequential vocalization.
Complex sequencing rules of birdsong can be explained by simple hidden Markov processes
Nov 11, 2010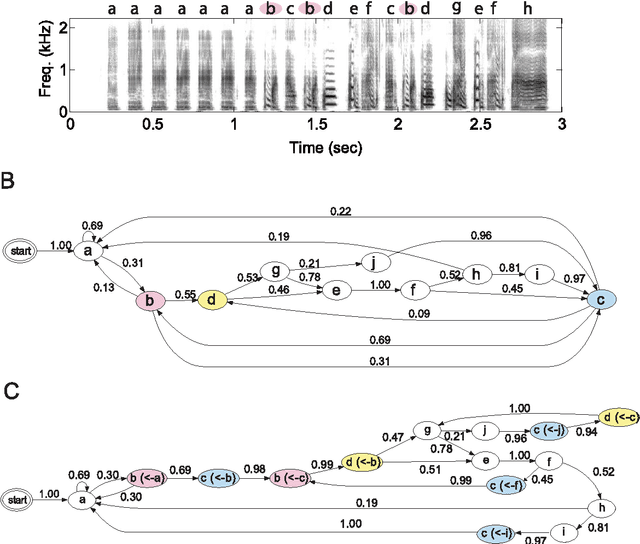
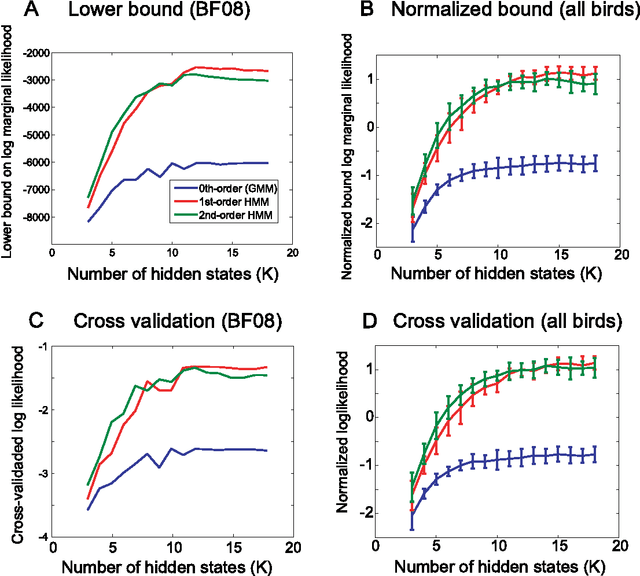
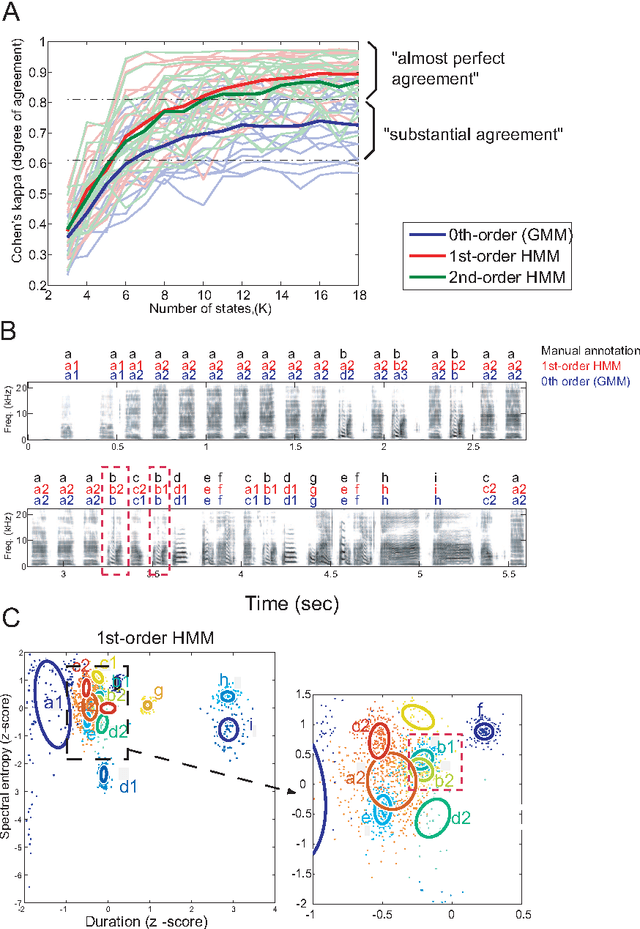
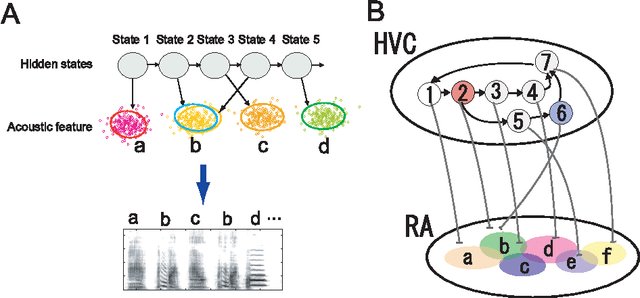
Complex sequencing rules observed in birdsongs provide an opportunity to investigate the neural mechanism for generating complex sequential behaviors. To relate the findings from studying birdsongs to other sequential behaviors, it is crucial to characterize the statistical properties of the sequencing rules in birdsongs. However, the properties of the sequencing rules in birdsongs have not yet been fully addressed. In this study, we investigate the statistical propertiesof the complex birdsong of the Bengalese finch (Lonchura striata var. domestica). Based on manual-annotated syllable sequences, we first show that there are significant higher-order context dependencies in Bengalese finch songs, that is, which syllable appears next depends on more than one previous syllable. This property is shared with other complex sequential behaviors. We then analyze acoustic features of the song and show that higher-order context dependencies can be explained using first-order hidden state transition dynamics with redundant hidden states. This model corresponds to hidden Markov models (HMMs), well known statistical models with a large range of application for time series modeling. The song annotation with these models with first-order hidden state dynamics agreed well with manual annotation, the score was comparable to that of a second-order HMM, and surpassed the zeroth-order model (the Gaussian mixture model (GMM)), which does not use context information. Our results imply that the hierarchical representation with hidden state dynamics may underlie the neural implementation for generating complex sequences with higher-order dependencies.