 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn end-to-end framework for gene expression classification by integrating a background knowledge graph: application to cancer prognosis prediction
Jun 29, 2023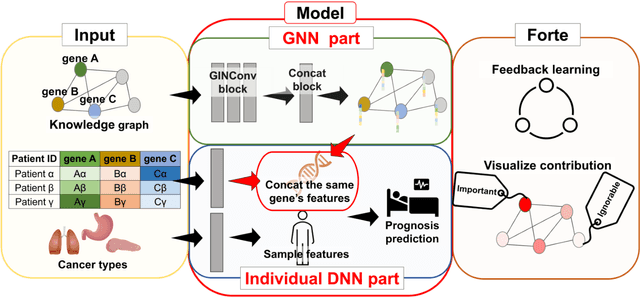
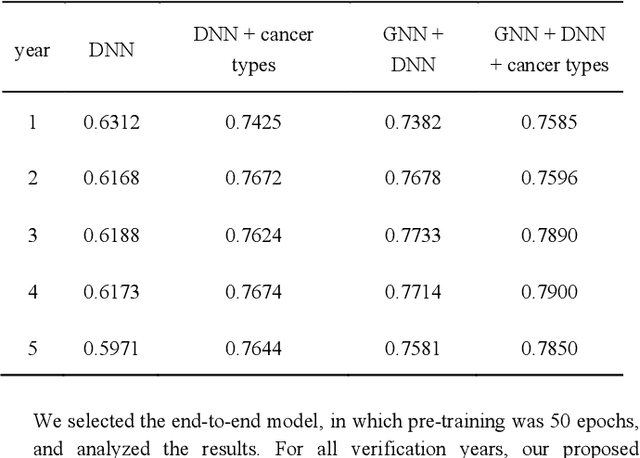
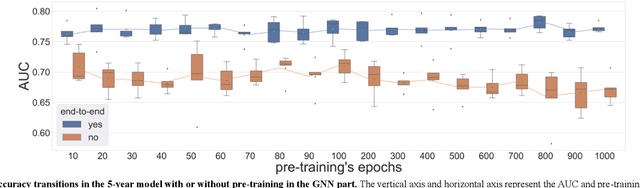
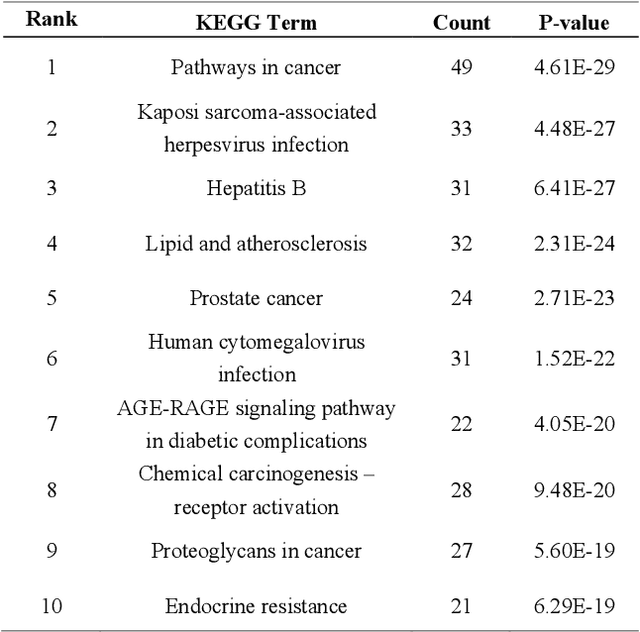
Biological data may be separated into primary data, such as gene expression, and secondary data, such as pathways and protein-protein interactions. Methods using secondary data to enhance the analysis of primary data are promising, because secondary data have background information that is not included in primary data. In this study, we proposed an end-to-end framework to integrally handle secondary data to construct a classification model for primary data. We applied this framework to cancer prognosis prediction using gene expression data and a biological network. Cross-validation results indicated that our model achieved higher accuracy compared with a deep neural network model without background biological network information. Experiments conducted in patient groups by cancer type showed improvement in ROC-area under the curve for many groups. Visualizations of high accuracy cancer types identified contributing genes and pathways by enrichment analysis. Known biomarkers and novel biomarker candidates were identified through these experiments.