 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Subset Stacking
Dec 12, 2021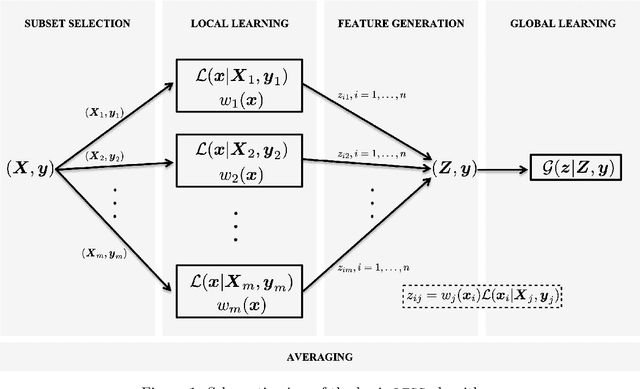


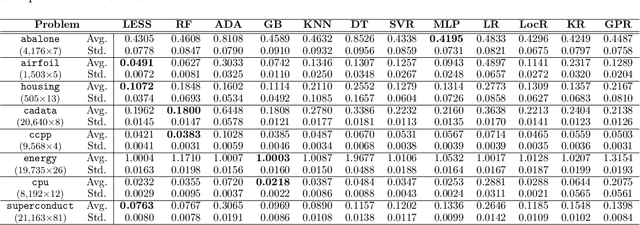
We propose a new algorithm that learns from a set of input-output pairs. Our algorithm is designed for populations where the relation between the input variables and the output variable exhibits a heterogeneous behavior across the predictor space. The algorithm starts with generating subsets that are concentrated around random points in the input space. This is followed by training a local predictor for each subset. Those predictors are then combined in a novel way to yield an overall predictor. We call this algorithm "LEarning with Subset Stacking" or LESS, due to its resemblance to method of stacking regressors. We compare the testing performance of LESS with the state-of-the-art methods on several datasets. Our comparison shows that LESS is a competitive supervised learning method. Moreover, we observe that LESS is also efficient in terms of computation time and it allows a straightforward parallel implementation.