 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is to be gained by ensemble models in analysis of spectroscopic data?
Apr 02, 2024An empirical study was carried out to compare different implementations of ensemble models aimed at improving prediction in spectroscopic data. A wide range of candidate models were fitted to benchmark datasets from regression and classification settings. A statistical analysis using linear mixed model was carried out on prediction performance criteria resulting from model fits over random splits of the data. The results showed that the ensemble classifiers were able to consistently outperform candidate models in our application
* 14 pages, 8 figures, 1 algorithm
Subjective assessment of the impact of a content adaptive optimiser for compressing 4K HDR content with AV1
Jun 26, 2023



Since 2015 video dimensionality has expanded to higher spatial and temporal resolutions and a wider colour gamut. This High Dynamic Range (HDR) content has gained traction in the consumer space as it delivers an enhanced quality of experience. At the same time, the complexity of codecs is growing. This has driven the development of tools for content-adaptive optimisation that achieve optimal rate-distortion performance for HDR video at 4K resolution. While improvements of just a few percentage points in BD-Rate (1-5\%) are significant for the streaming media industry, the impact on subjective quality has been less studied especially for HDR/AV1. In this paper, we conduct a subjective quality assessment (42 subjects) of 4K HDR content with a per-clip optimisation strategy. We correlate these subjective scores with existing popular objective metrics used in standard development and show that some perceptual metrics correlate surprisingly well even though they are not tuned for HDR. We find that the DSQCS protocol is too insensitive to categorically compare the methods but the data allows us to make recommendations about the use of experts vs non-experts in HDR studies, and explain the subjective impact of film grain in HDR content under compression.
Hierarchical Embedded Bayesian Additive Regression Trees
Apr 14, 2022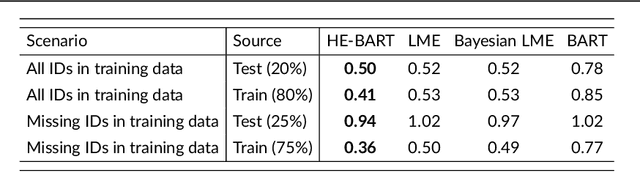
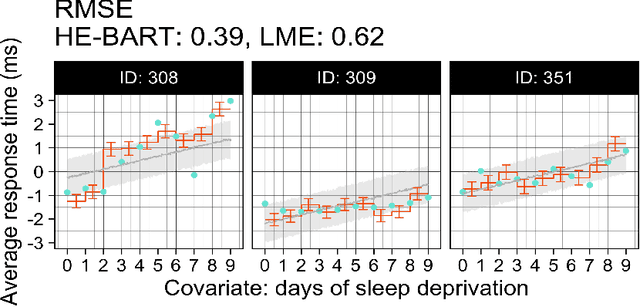
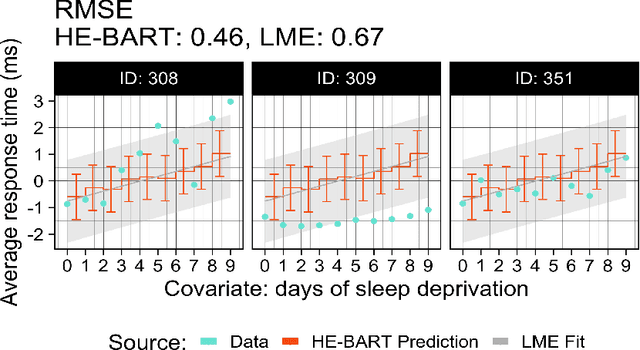
We propose a simple yet powerful extension of Bayesian Additive Regression Trees which we name Hierarchical Embedded BART (HE-BART). The model allows for random effects to be included at the terminal node level of a set of regression trees, making HE-BART a non-parametric alternative to mixed effects models which avoids the need for the user to specify the structure of the random effects in the model, whilst maintaining the prediction and uncertainty calibration properties of standard BART. Using simulated and real-world examples, we demonstrate that this new extension yields superior predictions for many of the standard mixed effects models' example data sets, and yet still provides consistent estimates of the random effect variances. In a future version of this paper, we outline its use in larger, more advanced data sets and structures.
Interactive slice visualization for exploring machine learning models
Jan 18, 2021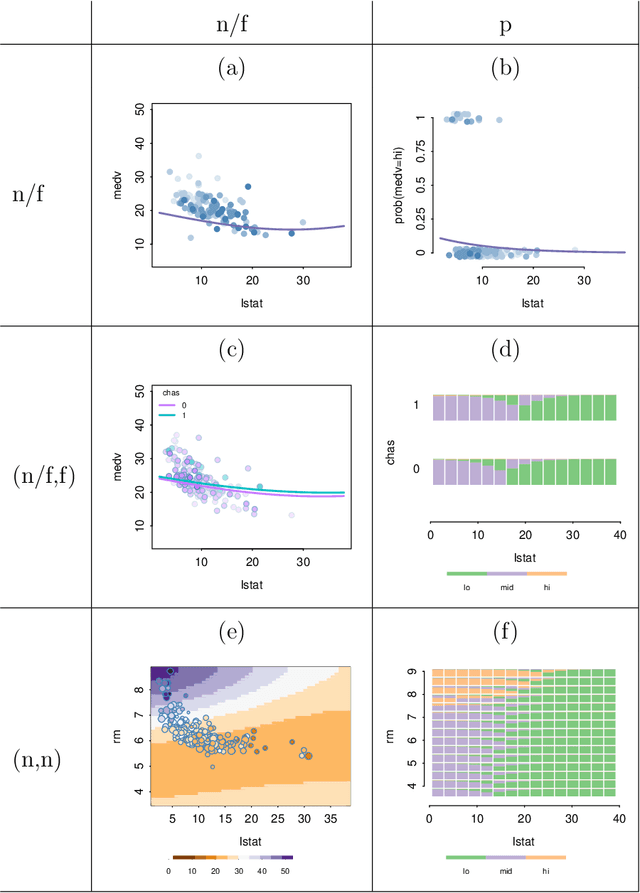
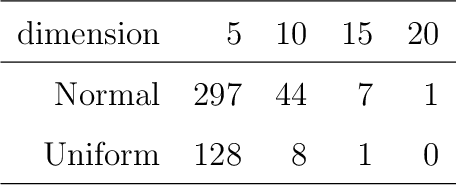
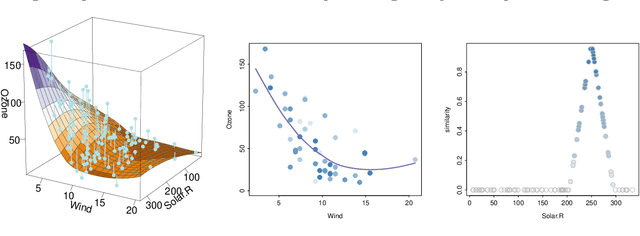
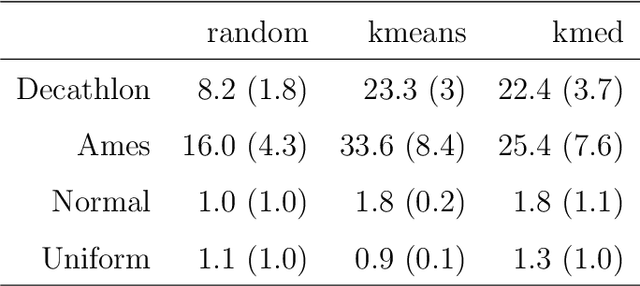
Machine learning models fit complex algorithms to arbitrarily large datasets. These algorithms are well-known to be high on performance and low on interpretability. We use interactive visualization of slices of predictor space to address the interpretability deficit; in effect opening up the black-box of machine learning algorithms, for the purpose of interrogating, explaining, validating and comparing model fits. Slices are specified directly through interaction, or using various touring algorithms designed to visit high-occupancy sections or regions where the model fits have interesting properties. The methods presented here are implemented in the R package \pkg{condvis2}.
Generalizing Gain Penalization for Feature Selection in Tree-based Models
Jun 12, 2020
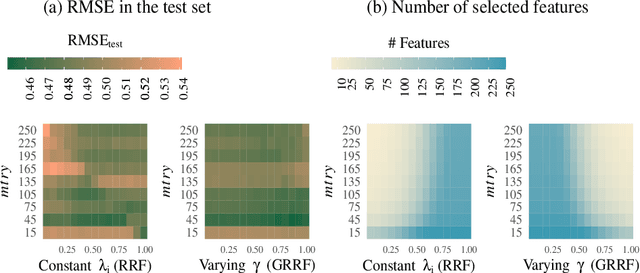
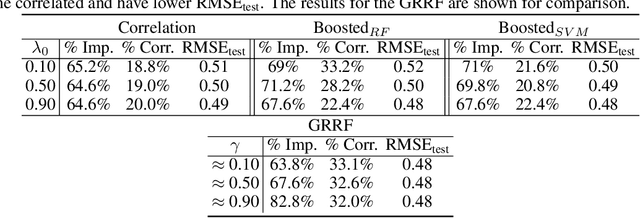

We develop a new approach for feature selection via gain penalization in tree-based models. First, we show that previous methods do not perform sufficient regularization and often exhibit sub-optimal out-of-sample performance, especially when correlated features are present. Instead, we develop a new gain penalization idea that exhibits a general local-global regularization for tree-based models. The new method allows for more flexibility in the choice of feature-specific importance weights. We validate our method on both simulated and real data and implement itas an extension of the popular R package ranger.
Comparison of Machine Learning Models in Food Authentication Studies
May 17, 2019


The underlying objective of food authentication studies is to determine whether unknown food samples have been correctly labelled. In this paper we study three near infrared (NIR) spectroscopic datasets from food samples of different types: meat samples (labelled by species), olive oil samples (labelled by their geographic origin) and honey samples (labelled as pure or adulterated by different adulterants). We apply and compare a large number of classification, dimension reduction and variable selection approaches to these datasets. NIR data pose specific challenges to classification and variable selection: the datasets are high - dimensional where the number of cases ($n$) $<<$ number of features ($p$) and the recorded features are highly serially correlated. In this paper we carry out comparative analysis of different approaches and find that partial least squares, a classic tool employed for these types of data, outperforms all the other approaches considered.