 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Polish to English Neural Machine Translation with Transfer Learning: Effects of Data Volume and Language Similarity
Jun 01, 2023
This paper investigates the impact of data volume and the use of similar languages on transfer learning in a machine translation task. We find out that having more data generally leads to better performance, as it allows the model to learn more patterns and generalizations from the data. However, related languages can also be particularly effective when there is limited data available for a specific language pair, as the model can leverage the similarities between the languages to improve performance. To demonstrate, we fine-tune mBART model for a Polish-English translation task using the OPUS-100 dataset. We evaluate the performance of the model under various transfer learning configurations, including different transfer source languages and different shot levels for Polish, and report the results. Our experiments show that a combination of related languages and larger amounts of data outperforms the model trained on related languages or larger amounts of data alone. Additionally, we show the importance of related languages in zero-shot and few-shot configurations.
Adapting Multilingual Speech Representation Model for a New, Underresourced Language through Multilingual Fine-tuning and Continued Pretraining
Jan 18, 2023
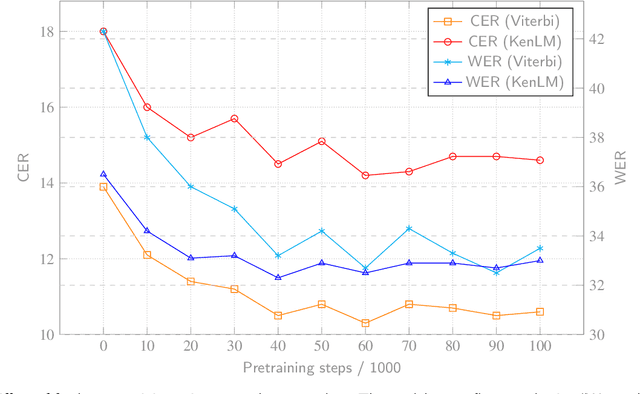

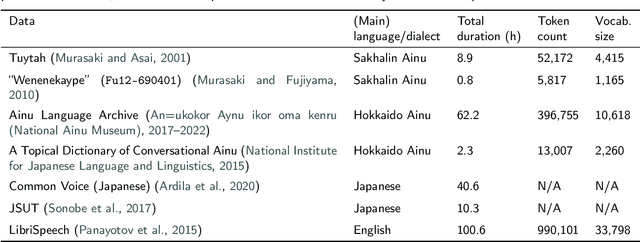
In recent years, neural models learned through self-supervised pretraining on large scale multilingual text or speech data have exhibited promising results for underresourced languages, especially when a relatively large amount of data from related language(s) is available. While the technology has a potential for facilitating tasks carried out in language documentation projects, such as speech transcription, pretraining a multilingual model from scratch for every new language would be highly impractical. We investigate the possibility for adapting an existing multilingual wav2vec 2.0 model for a new language, focusing on actual fieldwork data from a critically endangered tongue: Ainu. Specifically, we (i) examine the feasibility of leveraging data from similar languages also in fine-tuning; (ii) verify whether the model's performance can be improved by further pretraining on target language data. Our results show that continued pretraining is the most effective method to adapt a wav2vec 2.0 model for a new language and leads to considerable reduction in error rates. Furthermore, we find that if a model pretrained on a related speech variety or an unrelated language with similar phonological characteristics is available, multilingual fine-tuning using additional data from that language can have positive impact on speech recognition performance when there is very little labeled data in the target language.
* 14 pages
Can You Fool AI by Doing a 180? $\unicode{x2013}$ A Case Study on Authorship Analysis of Texts by Arata Osada
Jul 19, 2022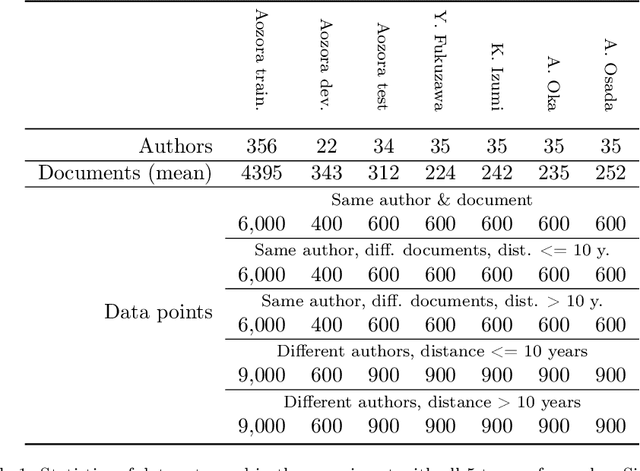
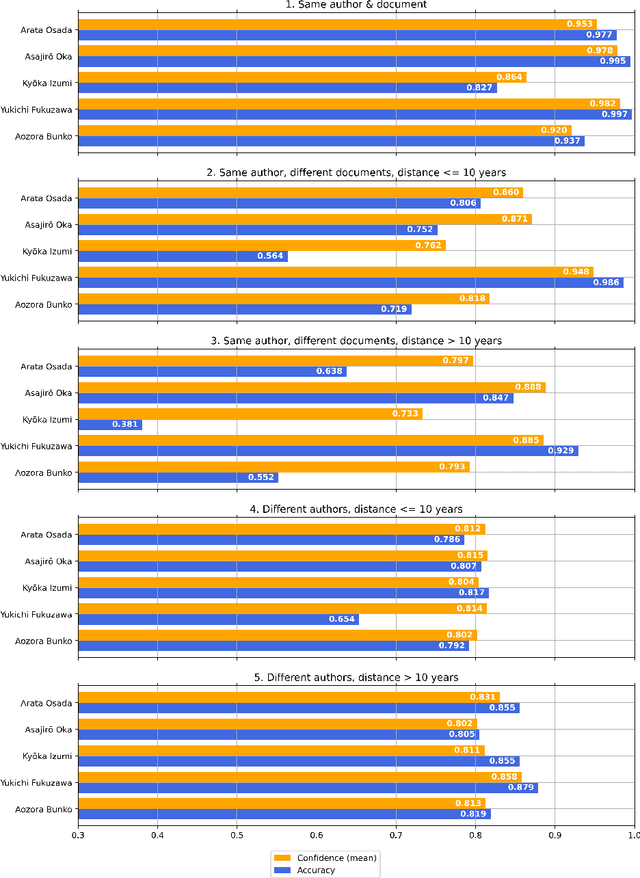
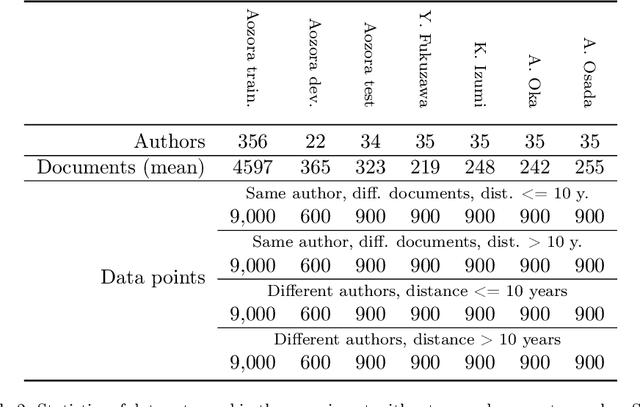
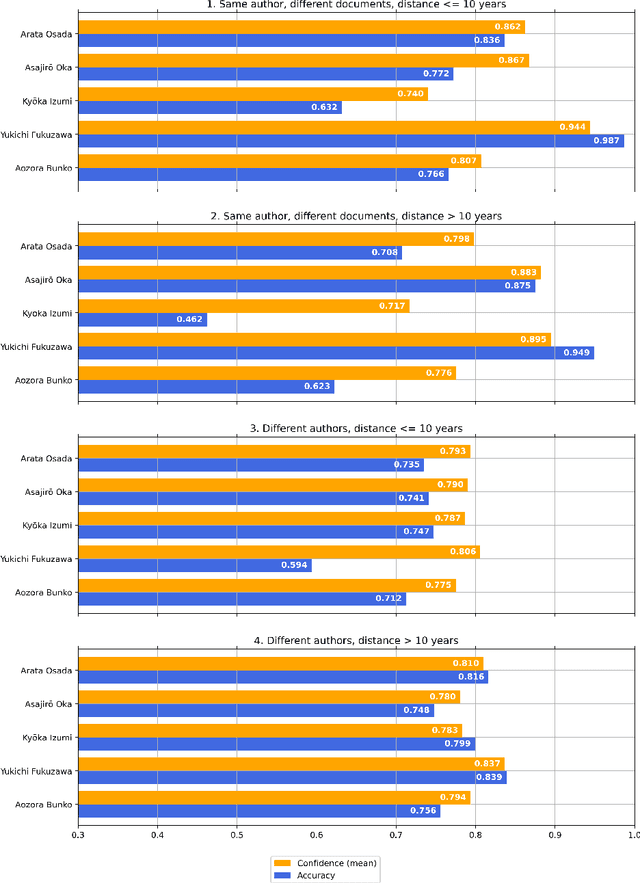
This paper is our attempt at answering a twofold question covering the areas of ethics and authorship analysis. Firstly, since the methods used for performing authorship analysis imply that an author can be recognized by the content he or she creates, we were interested in finding out whether it would be possible for an author identification system to correctly attribute works to authors if in the course of years they have undergone a major psychological transition. Secondly, and from the point of view of the evolution of an author's ethical values, we checked what it would mean if the authorship attribution system encounters difficulties in detecting single authorship. We set out to answer those questions through performing a binary authorship analysis task using a text classifier based on a pre-trained transformer model and a baseline method relying on conventional similarity metrics. For the test set, we chose works of Arata Osada, a Japanese educator and specialist in the history of education, with half of them being books written before the World War II and another half in the 1950s, in between which he underwent a transformation in terms of political opinions. As a result, we were able to confirm that in the case of texts authored by Arata Osada in a time span of more than 10 years, while the classification accuracy drops by a large margin and is substantially lower than for texts by other non-fiction writers, confidence scores of the predictions remain at a similar level as in the case of a shorter time span, indicating that the classifier was in many instances tricked into deciding that texts written over a time span of multiple years were actually written by two different people, which in turn leads us to believe that such a change can affect authorship analysis, and that historical events have great impact on a person's ethical outlook as expressed in their writings.