 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Multilingual Speech Representation Model for a New, Underresourced Language through Multilingual Fine-tuning and Continued Pretraining
Paper and Code

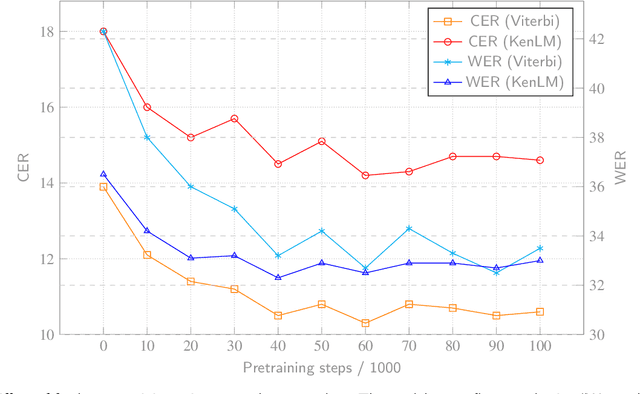

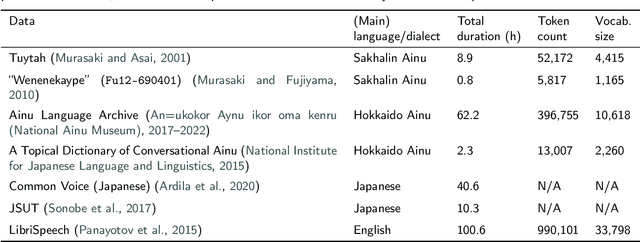
In recent years, neural models learned through self-supervised pretraining on large scale multilingual text or speech data have exhibited promising results for underresourced languages, especially when a relatively large amount of data from related language(s) is available. While the technology has a potential for facilitating tasks carried out in language documentation projects, such as speech transcription, pretraining a multilingual model from scratch for every new language would be highly impractical. We investigate the possibility for adapting an existing multilingual wav2vec 2.0 model for a new language, focusing on actual fieldwork data from a critically endangered tongue: Ainu. Specifically, we (i) examine the feasibility of leveraging data from similar languages also in fine-tuning; (ii) verify whether the model's performance can be improved by further pretraining on target language data. Our results show that continued pretraining is the most effective method to adapt a wav2vec 2.0 model for a new language and leads to considerable reduction in error rates. Furthermore, we find that if a model pretrained on a related speech variety or an unrelated language with similar phonological characteristics is available, multilingual fine-tuning using additional data from that language can have positive impact on speech recognition performance when there is very little labeled data in the target language.