 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RatioLog Project: Rational Extensions of Logical Reasoning
Jul 30, 2015


Higher-level cognition includes logical reasoning and the ability of question answering with common sense. The RatioLog project addresses the problem of rational reasoning in deep question answering by methods from automated deduction and cognitive computing. In a first phase, we combine techniques from information retrieval and machine learning to find appropriate answer candidates from the huge amount of text in the German version of the free encyclopedia "Wikipedia". In a second phase, an automated theorem prover tries to verify the answer candidates on the basis of their logical representations. In a third phase - because the knowledge may be incomplete and inconsistent -, we consider extensions of logical reasoning to improve the results. In this context, we work toward the application of techniques from human reasoning: We employ defeasible reasoning to compare the answers w.r.t. specificity, deontic logic, normative reasoning, and model construction. Moreover, we use integrated case-based reasoning and machine learning techniques on the basis of the semantic structure of the questions and answer candidates to learn giving the right answers.
* 7 pages, 3 figures
A Case Based Reasoning Approach for Answer Reranking in Question Answering
Mar 10, 2015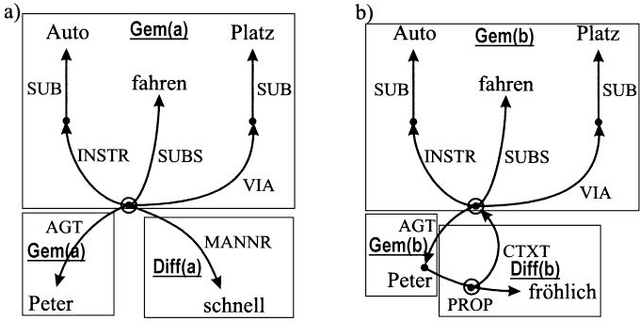

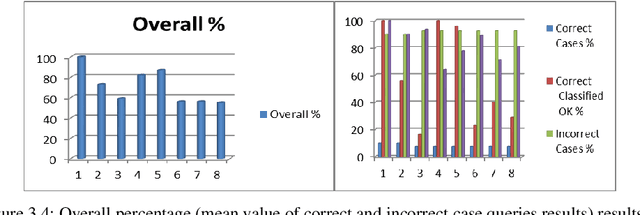
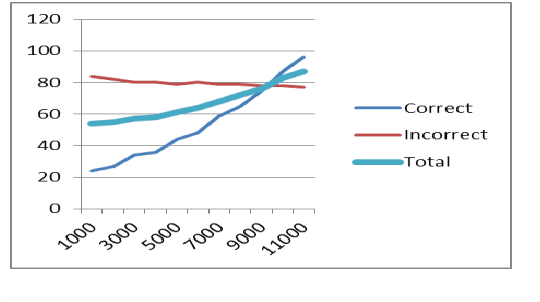
In this document I present an approach to answer validation and reranking for question answering (QA) systems. A cased-based reasoning (CBR) system judges answer candidates for questions from annotated answer candidates for earlier questions. The promise of this approach is that user feedback will result in improved answers of the QA system, due to the growing case base. In the paper, I present the adequate structuring of the case base and the appropriate selection of relevant similarity measures, in order to solve the answer validation problem. The structural case base is built from annotated MultiNet graphs, which provide representations for natural language expressions, and corresponding graph similarity measures. I cover a priori relations to experienced answer candidates for former questions. I compare the CBR System results to current approaches in an experiment integrating CBR into an existing framework for answer validation and reranking. This integration is achieved by adding CBR-related features to the input of a learned ranking model that determines the final answer ranking. In the experiments based on QA@CLEF questions, the best learned models make heavy use of CBR features. Observing the results with a continually growing case base, I present a positive effect of the size of the case base on the accuracy of the CBR subsystem.