 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
w2v-SELD: A Sound Event Localization and Detection Framework for Self-Supervised Spatial Audio Pre-Training
Dec 30, 2023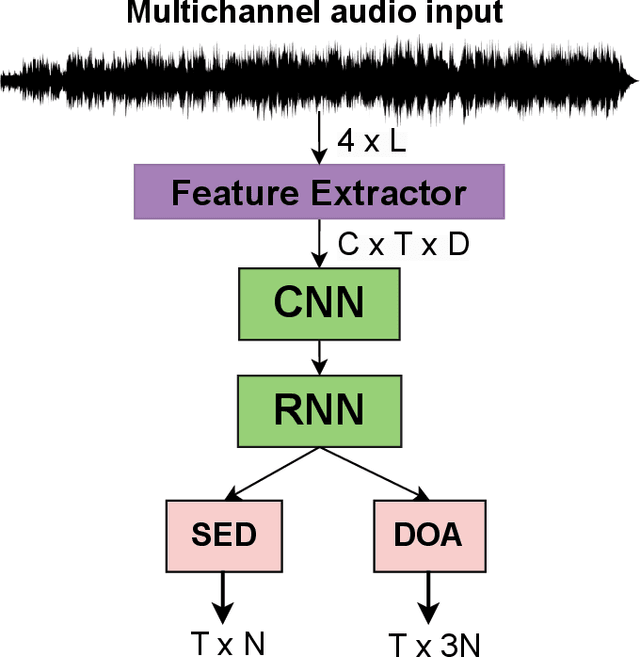

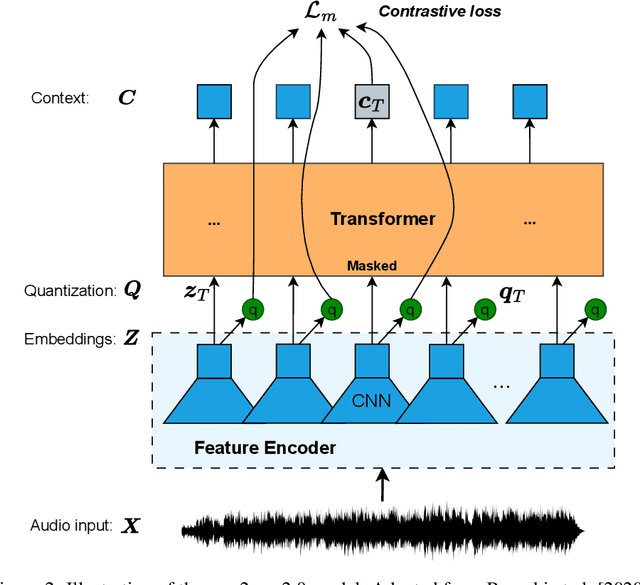

Sound Event Detection and Localization (SELD) constitutes a complex task that depends on extensive multichannel audio recordings with annotated sound events and their respective locations. In this paper, we introduce a self-supervised approach for SELD adapted from the pre-training methodology of wav2vec 2.0, which learns representations directly from raw audio data, eliminating the need for supervision. By applying this approach to SELD, we can leverage a substantial amount of unlabeled 3D audio data to learn robust representations of sound events and their locations. Our method comprises two primary stages: pre-training and fine-tuning. In the pre-training phase, unlabeled 3D audio datasets are utilized to train our w2v-SELD model, capturing intricate high-level features and contextual information inherent in audio signals. Subsequently, in the fine-tuning stage, a smaller dataset with labeled SELD data fine-tunes the pre-trained model. Experimental results on benchmark datasets demonstrate the effectiveness of the proposed self-supervised approach for SELD. The model surpasses baseline systems provided with the datasets and achieves competitive performance comparable to state-of-the-art supervised methods. The code and pre-trained parameters of our w2v-SELD model are available in this repository.
Song Emotion Recognition: a Performance Comparison Between Audio Features and Artificial Neural Networks
Sep 24, 2022
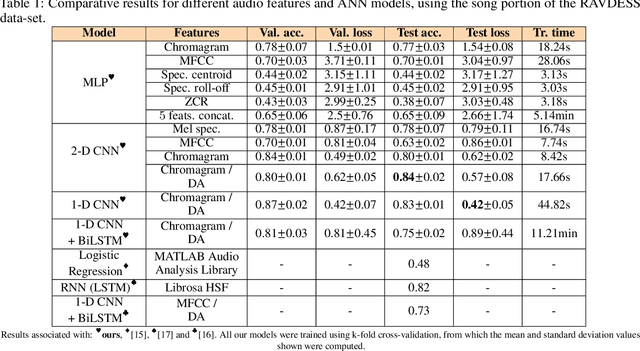
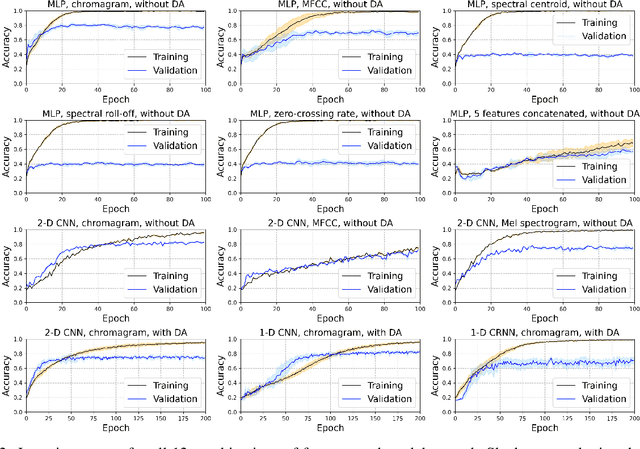
When songs are composed or performed, there is often an intent by the singer/songwriter of expressing feelings or emotions through it. For humans, matching the emotiveness in a musical composition or performance with the subjective perception of an audience can be quite challenging. Fortunately, the machine learning approach for this problem is simpler. Usually, it takes a data-set, from which audio features are extracted to present this information to a data-driven model, that will, in turn, train to predict what is the probability that a given song matches a target emotion. In this paper, we studied the most common features and models used in recent publications to tackle this problem, revealing which ones are best suited for recognizing emotion in a cappella songs.