 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgew2v-SELD: A Sound Event Localization and Detection Framework for Self-Supervised Spatial Audio Pre-Training
Paper and Code
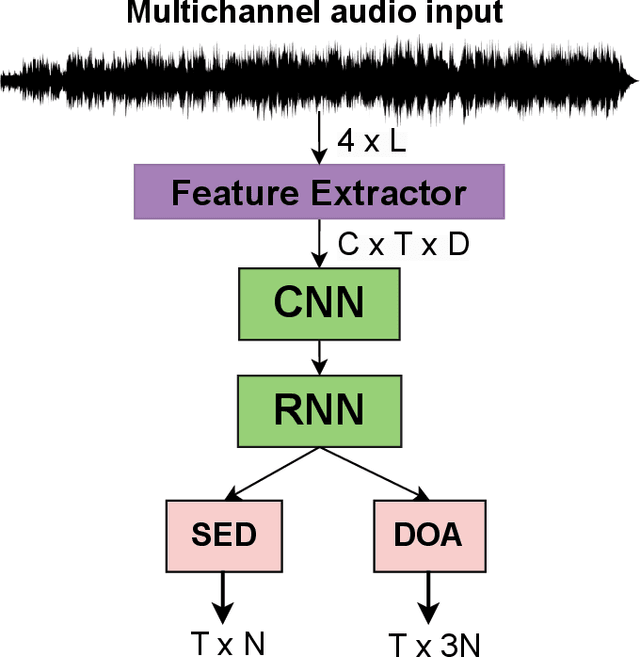

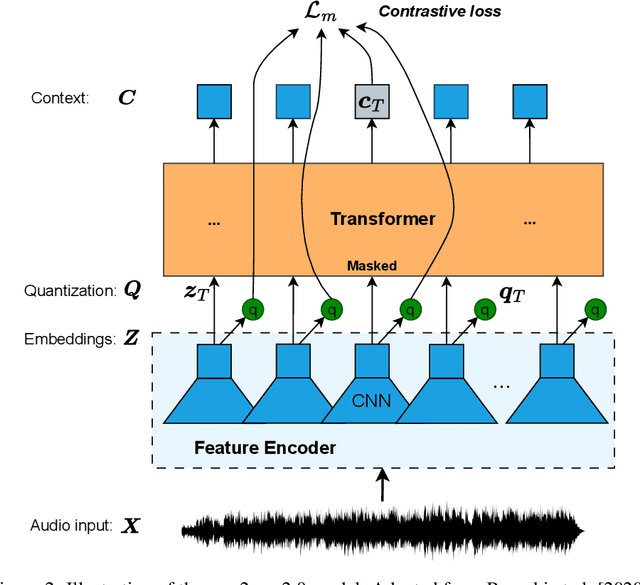

Sound Event Detection and Localization (SELD) constitutes a complex task that depends on extensive multichannel audio recordings with annotated sound events and their respective locations. In this paper, we introduce a self-supervised approach for SELD adapted from the pre-training methodology of wav2vec 2.0, which learns representations directly from raw audio data, eliminating the need for supervision. By applying this approach to SELD, we can leverage a substantial amount of unlabeled 3D audio data to learn robust representations of sound events and their locations. Our method comprises two primary stages: pre-training and fine-tuning. In the pre-training phase, unlabeled 3D audio datasets are utilized to train our w2v-SELD model, capturing intricate high-level features and contextual information inherent in audio signals. Subsequently, in the fine-tuning stage, a smaller dataset with labeled SELD data fine-tunes the pre-trained model. Experimental results on benchmark datasets demonstrate the effectiveness of the proposed self-supervised approach for SELD. The model surpasses baseline systems provided with the datasets and achieves competitive performance comparable to state-of-the-art supervised methods. The code and pre-trained parameters of our w2v-SELD model are available in this repository.