 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligibility of Speech in Noise: Investigating Contribution of Magnitude and Phase Spectra
Jun 15, 2026It is well known that intelligibility of speech reduces in the presence of ambient noise. However, studies show that all sounds are not affected uniformly (or equally) and that vowels are more robust to noise than consonants. In this study, intelligibility of various consonants is assessed and analyzed in stationary white noise and non-stationary babble noise conditions. Specifically, this study investigates the individual contribution of magnitude and phase spectra of a given speech signal on human speech recognition of consonants in noisy conditions. In this regard, three experiments are carried out. In experiment 1, clean signal, signal reconstructed with only magnitude spectrum information (magnitude only signal) and signal reconstructed with only phase spectrum information (phase only signal) are assessed for intelligibility. In experiment 2, noise is added to clean speech. From noisy speech, phase only signal and magnitude only signal are reconstructed and intelligibility tests are performed for all these three signals. In experiment 3, noise is added directly to the magnitude only and phase only signals reconstructed from clean speech and their intelligibility is assessed. Results of these experiments show that magnitude spectrum contributes more to intelligibility in clean condition than phase spectrum, while information from phase spectrum is more robust in noisy conditions. It is also observed that, among consonants, nasals are more susceptible to noise whereas fricatives and approximants were observed to be comparatively more robust.
SHIELD8-UAV: Sequential 8-bit Hardware Implementation of a Precision-Aware 1D-F-CNN for Low-Energy UAV Acoustic Detection and Temporal Tracking
Mar 01, 2026Real-time unmanned aerial vehicle (UAV) acoustic detection at the edge demands low-latency inference under strict power and hardware limits. This paper presents SHIELD8-UAV, a sequential 8-bit hardware implementation of a precision-aware 1D feature-driven CNN (1D-F-CNN) accelerator for continuous acoustic monitoring. The design performs layer-wise execution on a shared multi-precision datapath, eliminating the need for replicated processing elements. A layer-sensitivity quantisation framework supports FP32, BF16, INT8, and FXP8 modes, while structured channel pruning reduces the flattened feature dimension from 35,072 to 8,704 (75%), thereby lowering serialised dense-layer cycles. The model achieves 89.91% detection accuracy in FP32 with less than 2.5% degradation in 8-bit modes. The accelerator uses 2,268 LUTs and 0.94 W power with 116 ms end-to-end latency, achieving 37.8% and 49.6% latency reduction compared with QuantMAC and LPRE, respectively, on a Pynq-Z2 FPGA, and 5-9% lower logic usage than parallel designs. ASIC synthesis in UMC 40 nm technology shows a maximum operating frequency of 1.56 GHz, 3.29 mm2 core area, and 1.65 W total power. These results demonstrate that sequential execution combined with precision-aware quantisation and serialisation-aware pruning enables practical low-energy edge inference without relying on massive parallelism.
Computing Optimal Location of Microphone for Improved Speech Recognition
Mar 24, 2022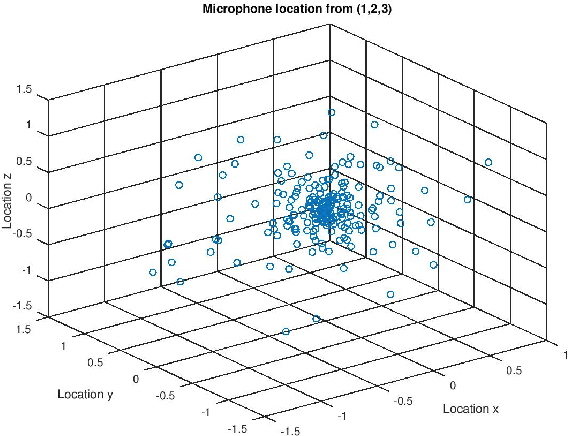
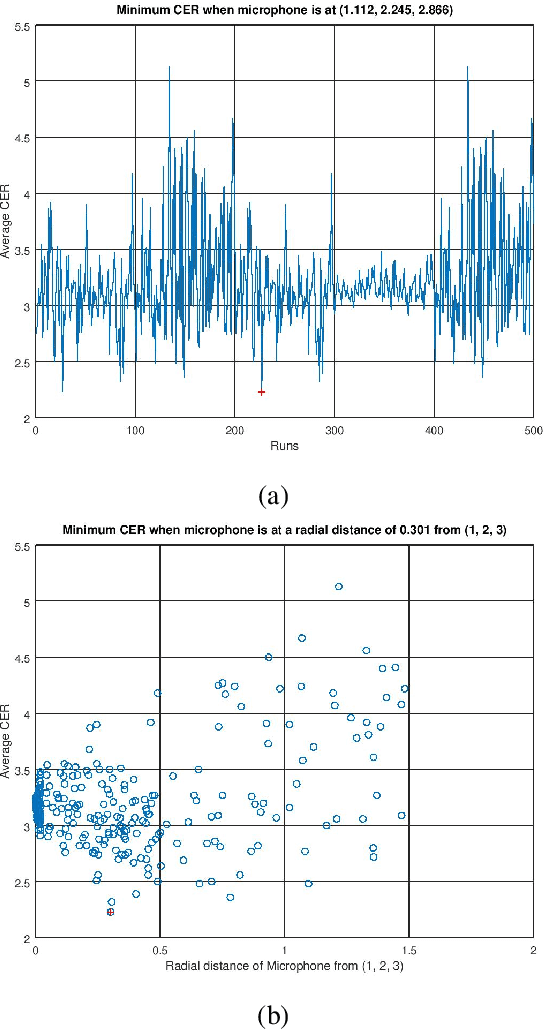
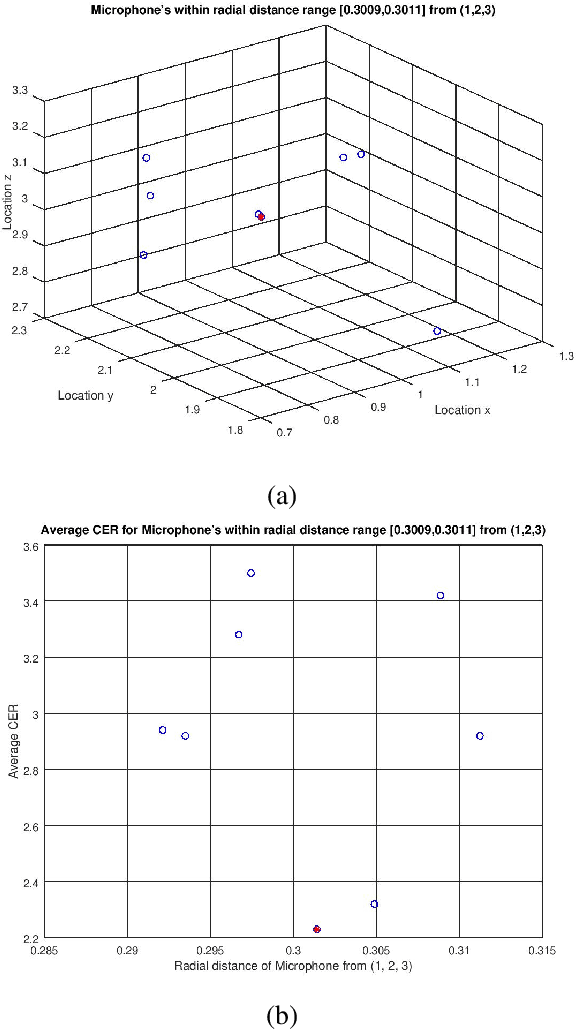
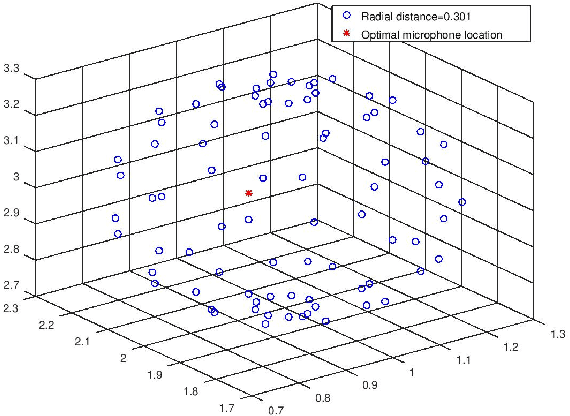
It was shown in our earlier work that the measurement error in the microphone position affected the room impulse response (RIR) which in turn affected the single-channel close microphone and multi-channel distant microphone speech recognition. In this paper, as an extension, we systematically study to identify the optimal location of the microphone, given an approximate and hence erroneous location of the microphone in 3D space. The primary idea is to use Monte-Carlo technique to generate a large number of random microphone positions around the erroneous microphone position and select the microphone position that results in the best performance of a general purpose automatic speech recognition (gp-asr). We experiment with clean and noisy speech and show that the optimal location of the microphone is unique and is affected by noise.
Using Deep Learning Techniques and Inferential Speech Statistics for AI Synthesised Speech Recognition
Jul 23, 2021
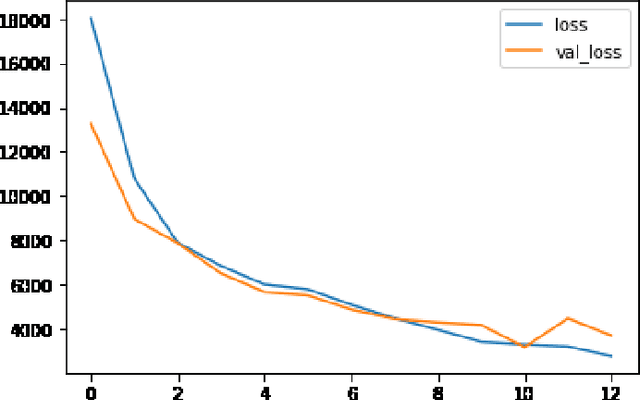
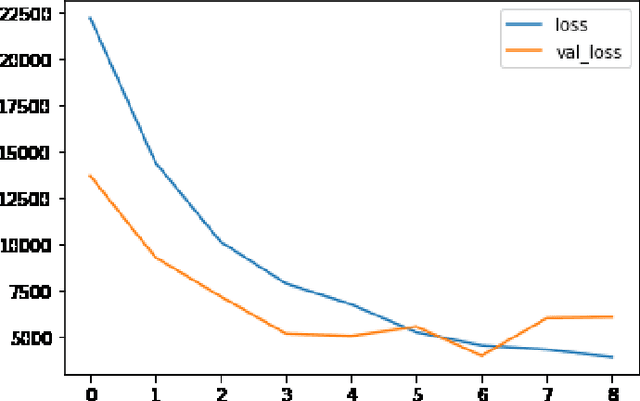
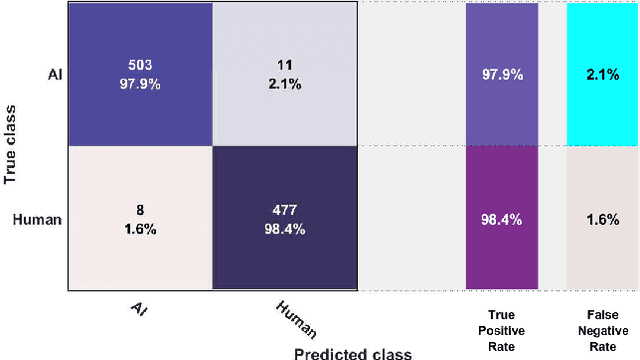
The recent developments in technology have re-warded us with amazing audio synthesis models like TACOTRON and WAVENETS. On the other side, it poses greater threats such as speech clones and deep fakes, that may go undetected. To tackle these alarming situations, there is an urgent need to propose models that can help discriminate a synthesized speech from an actual human speech and also identify the source of such a synthesis. Here, we propose a model based on Convolutional Neural Network (CNN) and Bidirectional Recurrent Neural Network (BiRNN) that helps to achieve both the aforementioned objectives. The temporal dependencies present in AI synthesized speech are exploited using Bidirectional RNN and CNN. The model outperforms the state-of-the-art approaches by classifying the AI synthesized audio from real human speech with an error rate of 1.9% and detecting the underlying architecture with an accuracy of 97%.