 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-Facial Expression Recognition in Video Based on Optimal Convolutional Neural Network (MFEOCNN) Algorithm
Sep 29, 2020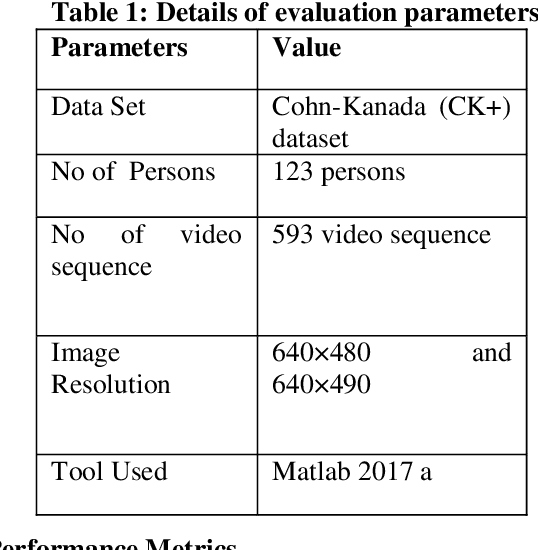
Facial expression is a standout amongst the most imperative features of human emotion recognition. For demonstrating the emotional states facial expressions are utilized by the people. In any case, recognition of facial expressions has persisted a testing and intriguing issue with regards to PC vision. Recognizing the Micro-Facial expression in video sequence is the main objective of the proposed approach. For efficient recognition, the proposed method utilizes the optimal convolution neural network. Here the proposed method considering the input dataset is the CK+ dataset. At first, by means of Adaptive median filtering preprocessing is performed in the input image. From the preprocessed output, the extracted features are Geometric features, Histogram of Oriented Gradients features and Local binary pattern features. The novelty of the proposed method is, with the help of Modified Lion Optimization (MLO) algorithm, the optimal features are selected from the extracted features. In a shorter computational time, it has the benefits of rapidly focalizing and effectively acknowledging with the aim of getting an overall arrangement or idea. Finally, the recognition is done by Convolution Neural network (CNN). Then the performance of the proposed MFEOCNN method is analysed in terms of false measures and recognition accuracy. This kind of emotion recognition is mainly used in medicine, marketing, E-learning, entertainment, law and monitoring. From the simulation, we know that the proposed approach achieves maximum recognition accuracy of 99.2% with minimum Mean Absolute Error (MAE) value. These results are compared with the existing for MicroFacial Expression Based Deep-Rooted Learning (MFEDRL), Convolutional Neural Network with Lion Optimization (CNN+LO) and Convolutional Neural Network (CNN) without optimization. The simulation of the proposed method is done in the working platform of MATLAB.
A Study on Lip Localization Techniques used for Lip reading from a Video
Sep 28, 2020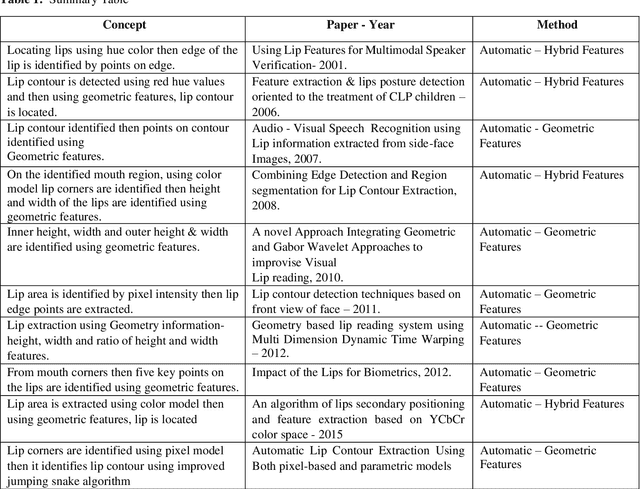

In this paper some of the different techniques used to localize the lips from the face are discussed and compared along with its processing steps. Lip localization is the basic step needed to read the lips for extracting visual information from the video input. The techniques could be applied on asymmetric lips and also on the mouth with visible teeth, tongue & mouth with moustache. In the process of Lip reading the following steps are generally used. They are, initially locating lips in the first frame of the video input, then tracking the lips in the following frames using the resulting pixel points of initial step and at last converting the tracked lip model to its corresponding matched letter to give the visual information. A new proposal is also initiated from the discussed techniques. The lip reading is useful in Automatic Speech Recognition when the audio is absent or present low with or without noise in the communication systems. Human Computer communication also will require speech recognition.
Efficient DWT-based fusion techniques using genetic algorithm for optimal parameter estimation
Sep 22, 2020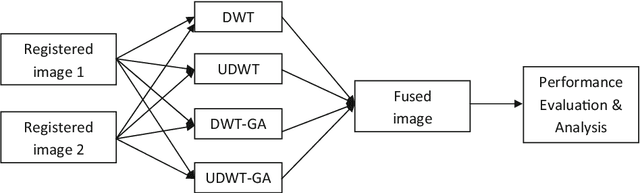

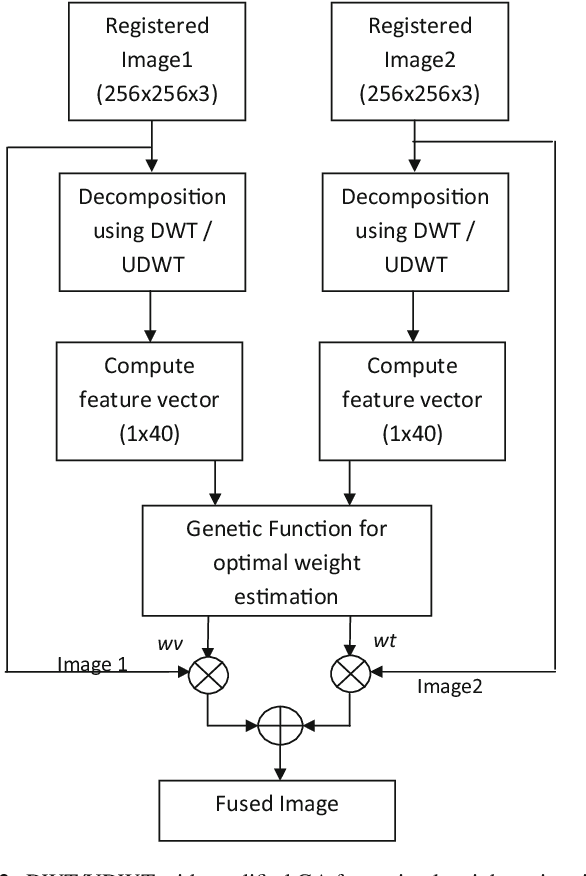

Image fusion plays a vital role in medical imaging. Image fusion aims to integrate complementary as well as redundant information from multiple modalities into a single fused image without distortion or loss of information. In this research work, discrete wavelet transform (DWT)and undecimated discrete wavelet transform (UDWT)-based fusion techniques using genetic algorithm (GA)foroptimalparameter(weight)estimationinthefusionprocessareimplemented and analyzed with multi-modality brain images. The lack of shift variance while performing image fusion using DWT is addressed using UDWT. The proposed fusion model uses an efficient, modified GA in DWT and UDWT for optimal parameter estimation, to improve the image quality and contrast. The complexity of the basic GA (pixel level) has been reduced in the modified GA (feature level), by limiting the search space. It is observed from our experiments that fusion using DWT and UDWT techniques with GA for optimal parameter estimation resulted in a better fused image in the aspects of retaining the information and contrast without error, both in human perception as well as evaluation using objective metrics. The contributions of this research work are (1) reduced time and space complexity in estimating the weight values using GA for fusion (2) system is scalable for input image of any size with similar time complexity, owing to feature level GA implementation and (3) identification of source image that contributes more to the fused image, from the weight values estimated.
Features based Mammogram Image Classification using Weighted Feature Support Vector Machine
Sep 19, 2020

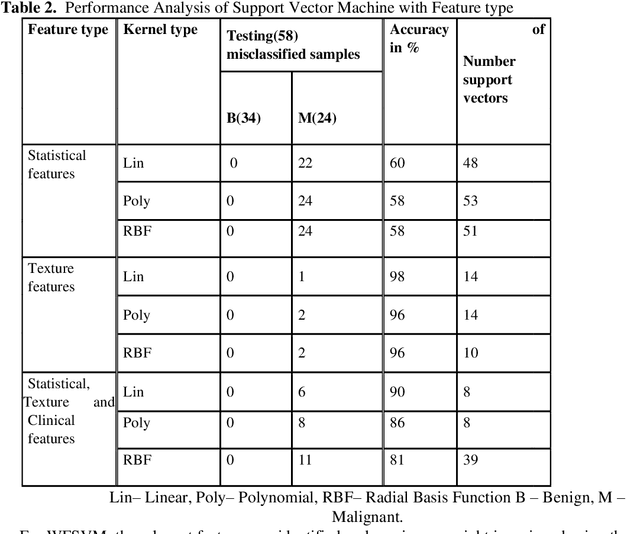

In the existing research of mammogram image classification, either clinical data or image features of a specific type is considered along with the supervised classifiers such as Neural Network (NN) and Support Vector Machine (SVM). This paper considers automated classification of breast tissue type as benign or malignant using Weighted Feature Support Vector Machine (WFSVM) through constructing the precomputed kernel function by assigning more weight to relevant features using the principle of maximizing deviations. Initially, MIAS dataset of mammogram images is divided into training and test set, then the preprocessing techniques such as noise removal and background removal are applied to the input images and the Region of Interest (ROI) is identified. The statistical features and texture features are extracted from the ROI and the clinical features are obtained directly from the dataset. The extracted features of the training dataset are used to construct the weighted features and precomputed linear kernel for training the WFSVM, from which the training model file is created. Using this model file the kernel matrix of test samples is classified as benign or malignant. This analysis shows that the texture features have resulted in better accuracy than the other features with WFSVM and SVM. However, the number of support vectors created in WFSVM is less than the SVM classifier.
* 9 pages, 3 figures, "submitted to International Conference on Computing and Communication Systems"
A Review of Visual Descriptors and Classification Techniques Used in Leaf Species Identification
Sep 13, 2020



Plants are fundamentally important to life. Key research areas in plant science include plant species identification, weed classification using hyper spectral images, monitoring plant health and tracing leaf growth, and the semantic interpretation of leaf information. Botanists easily identify plant species by discriminating between the shape of the leaf, tip, base, leaf margin and leaf vein, as well as the texture of the leaf and the arrangement of leaflets of compound leaves. Because of the increasing demand for experts and calls for biodiversity, there is a need for intelligent systems that recognize and characterize leaves so as to scrutinize a particular species, the diseases that affect them, the pattern of leaf growth, and so on. We review several image processing methods in the feature extraction of leaves, given that feature extraction is a crucial technique in computer vision. As computers cannot comprehend images, they are required to be converted into features by individually analysing image shapes, colours, textures and moments. Images that look the same may deviate in terms of geometric and photometric variations. In our study, we also discuss certain machine learning classifiers for an analysis of different species of leaves.
* 44 pages, 7 figures, "for final published version, see https://link.springer.com/article/10.1007/s11831-018-9266-3"
Micro-Facial Expression Recognition Based on Deep-Rooted Learning Algorithm
Sep 12, 2020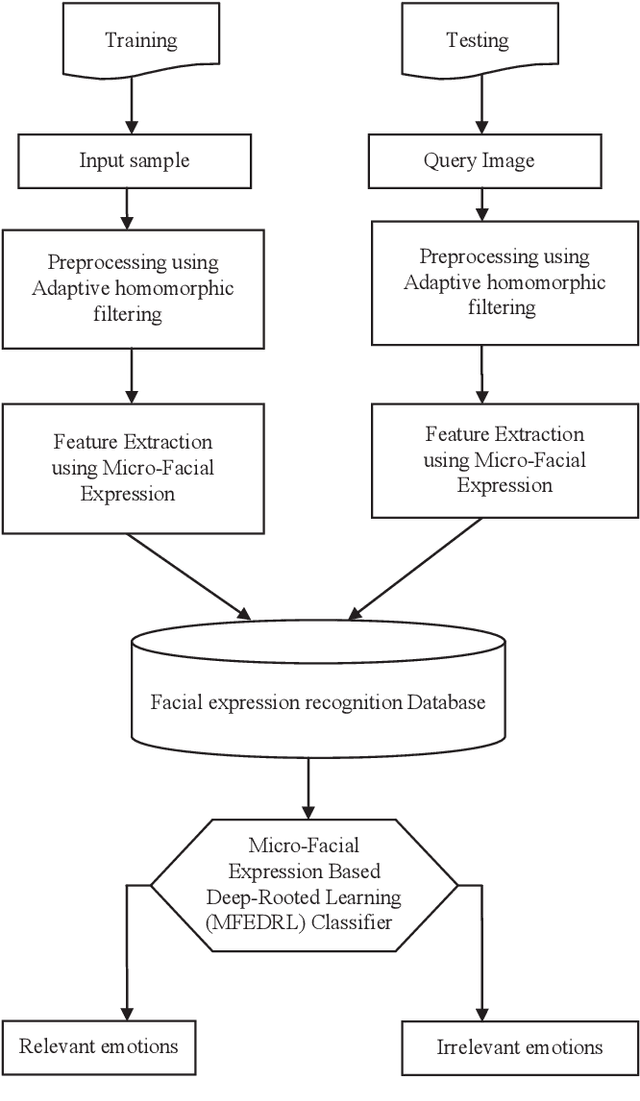



Facial expressions are important cues to observe human emotions. Facial expression recognition has attracted many researchers for years, but it is still a challenging topic since expression features vary greatly with the head poses, environments, and variations in the different persons involved. In this work, three major steps are involved to improve the performance of micro-facial expression recognition. First, an Adaptive Homomorphic Filtering is used for face detection and rotation rectification processes. Secondly, Micro-facial features were used to extract the appearance variations of a testing image-spatial analysis. The features of motion information are used for expression recognition in a sequence of facial images. An effective Micro-Facial Expression Based Deep-Rooted Learning (MFEDRL) classifier is proposed in this paper to better recognize spontaneous micro-expressions by learning parameters on the optimal features. This proposed method includes two loss functions such as cross entropy loss function and centre loss function. Then the performance of the algorithm will be evaluated using recognition rate and false measures. Simulation results show that the predictive performance of the proposed method outperforms that of the existing classifiers such as Convolutional Neural Network (CNN), Deep Neural Network (DNN), Artificial Neural Network (ANN), Support Vector Machine (SVM), and k-Nearest Neighbours (KNN) in terms of accuracy and Mean Absolute Error (MAE).
* 20 pages, 7 figures, "for the published version of the article, see https://www.atlantis-press.com/journals/ijcis/125915627"
A novel action recognition system for smart monitoring of elderly people using Action Pattern Image and Series CNN with transfer learning
Sep 07, 2020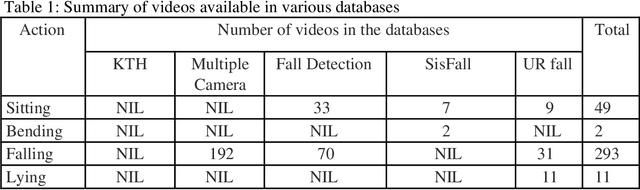


Falling of elderly people who are staying alone at home leads to health risks. If they are not attended immediately even it may lead to fatal danger to their life. In this paper a novel computer vision-based system for smart monitoring of elderly people using Series Convolutional Neural Network (SCNN) with transfer learning is proposed. When CNN is trained by the frames of the videos directly, it learns from all pixels including the background pixels. Generally, the background in a video does not contribute anything in identifying the action and actually it will mislead the action classification. So, we propose a novel action recognition system and our contributions are 1) to generate more general action patterns which are not affected by illumination and background variations of the video sequences and eliminate the obligation of image augmentation in CNN training 2) to design SCNN architecture and enhance the feature extraction process to learn large amount of data, 3) to present the patterns learnt by the neurons in the layers and analyze how these neurons capture the action when the input pattern is passing through these neurons, and 4) to extend the capability of the trained SCNN for recognizing fall actions using transfer learning.
A Review on Near Duplicate Detection of Images using Computer Vision Techniques
Sep 07, 2020



Nowadays, digital content is widespread and simply redistributable, either lawfully or unlawfully. For example, after images are posted on the internet, other web users can modify them and then repost their versions, thereby generating near-duplicate images. The presence of near-duplicates affects the performance of the search engines critically. Computer vision is concerned with the automatic extraction, analysis and understanding of useful information from digital images. The main application of computer vision is image understanding. There are several tasks in image understanding such as feature extraction, object detection, object recognition, image cleaning, image transformation, etc. There is no proper survey in literature related to near duplicate detection of images. In this paper, we review the state-of-the-art computer vision-based approaches and feature extraction methods for the detection of near duplicate images. We also discuss the main challenges in this field and how other researchers addressed those challenges. This review provides research directions to the fellow researchers who are interested to work in this field.