 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning algorithms for regret minimization in structured Markov Decision Processes
Aug 17, 2016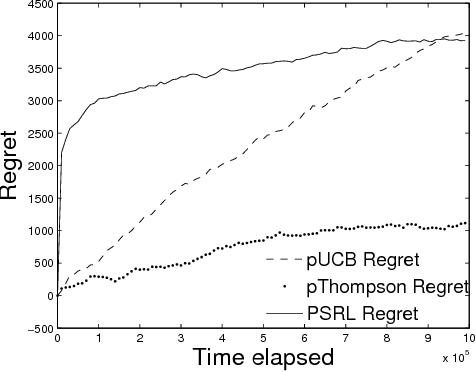
A recent goal in the Reinforcement Learning (RL) framework is to choose a sequence of actions or a policy to maximize the reward collected or minimize the regret incurred in a finite time horizon. For several RL problems in operation research and optimal control, the optimal policy of the underlying Markov Decision Process (MDP) is characterized by a known structure. The current state of the art algorithms do not utilize this known structure of the optimal policy while minimizing regret. In this work, we develop new RL algorithms that exploit the structure of the optimal policy to minimize regret. Numerical experiments on MDPs with structured optimal policies show that our algorithms have better performance, are easy to implement, have a smaller run-time and require less number of random number generations.