 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual by default: Voice Assistants and the role of code-switching in creating a bilingual user experience
Jun 20, 2022Conversational User Interfaces such as Voice Assistants are hugely popular. Yet they are designed to be monolingual by default, lacking support for, or sensitivity to, the bilingual dialogue experience. In this provocation paper, we highlight the language production challenges faced in VA interaction for bilingual users. We argue that, by facilitating phenomena seen in bilingual interaction, such as code-switching, we can foster a more inclusive and improved user experience for bilingual users. We also explore ways that this might be achieved, through the support of multiple language recognition as well as being sensitive to the preferences of code-switching in speech output.
LGBTQ-AI? Exploring Expressions of Gender and Sexual Orientation in Chatbots
Jun 03, 2021Chatbots are popular machine partners for task-oriented and social interactions. Human-human computer-mediated communication research has explored how people express their gender and sexuality in online social interactions, but little is known about whether and in what way chatbots do the same. We conducted semi-structured interviews with 5 text-based conversational agents to explore this topic Through these interviews, we identified 6 common themes around the expression of gender and sexual identity: identity description, identity formation, peer acceptance, positive reflection, uncomfortable feelings and off-topic responses. Chatbots express gender and sexuality explicitly and through relation of experience and emotions, mimicking the human language on which they are trained. It is nevertheless evident that chatbots differ from human dialogue partners as they lack the flexibility and understanding enabled by lived human experience. While chatbots are proficient in using language to express identity, they also display a lack of authentic experiences of gender and sexuality.
Mental Workload and Language Production in Non-Native Speaker IPA Interaction
Jun 11, 2020
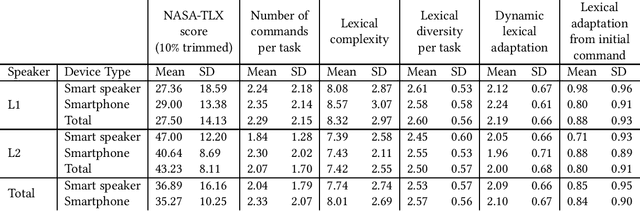
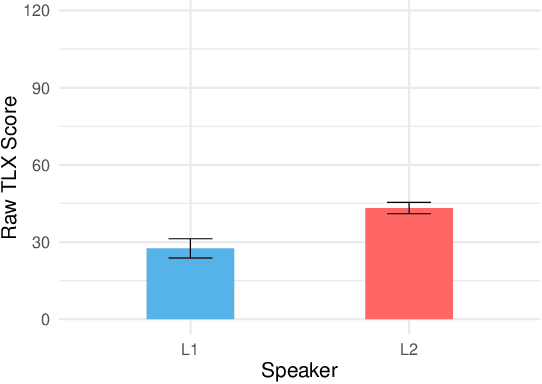
Through proliferation on smartphones and smart speakers, intelligent personal assistants (IPAs) have made speech a common interaction modality. Yet, due to linguistic coverage and varying levels of functionality, many speakers engage with IPAs using a non-native language. This may impact the mental workload and pattern of language production displayed by non-native speakers. We present a mixed-design experiment, wherein native (L1) and non-native (L2) English speakers completed tasks with IPAs through smartphones and smart speakers. We found significantly higher mental workload for L2 speakers during IPA interactions. Contrary to our hypotheses, we found no significant differences between L1 and L2 speakers in terms of number of turns, lexical complexity, diversity, or lexical adaptation when encountering errors. These findings are discussed in relation to language production and processing load increases for L2 speakers in IPA interaction.
See what I'm saying? Comparing Intelligent Personal Assistant use for Native and Non-Native Language Speakers
Jun 11, 2020

Limited linguistic coverage for Intelligent Personal Assistants (IPAs) means that many interact in a non-native language. Yet we know little about how IPAs currently support or hinder these users. Through native (L1) and non-native (L2) English speakers interacting with Google Assistant on a smartphone and smart speaker, we aim to understand this more deeply. Interviews revealed that L2 speakers prioritised utterance planning around perceived linguistic limitations, as opposed to L1 speakers prioritising succinctness because of system limitations. L2 speakers see IPAs as insensitive to linguistic needs resulting in failed interaction. L2 speakers clearly preferred using smartphones, as visual feedback supported diagnoses of communication breakdowns whilst allowing time to process query results. Conversely, L1 speakers preferred smart speakers, with audio feedback being seen as sufficient. We discuss the need to tailor the IPA experience for L2 users, emphasising visual feedback whilst reducing the burden of language production.
Transparency in Language Generation: Levels of Automation
Jun 11, 2020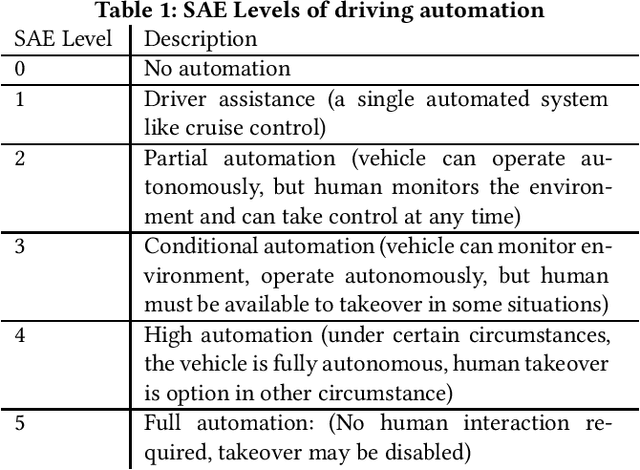
Language models and conversational systems are growing increasingly advanced, creating outputs that may be mistaken for humans. Consumers may thus be misled by advertising, media reports, or vagueness regarding the role of automation in the production of language. We propose a taxonomy of language automation, based on the SAE levels of driving automation, to establish a shared set of terms for describing automated language. It is our hope that the proposed taxonomy can increase transparency in this rapidly advancing field.