 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBattery health reporting fails independent validation across manufacturers
Mar 23, 2026Battery state-of-health (SOH) reported by on-board battery management systems (BMS) is the primary metric available to electric vehicle (EV) owners and regulators, yet no study has validated its reliability across manufacturers against independent measurements. Here we show, through an epidemiological study of 1,114 EVs spanning five manufacturers and 375 days, that battery health reporting is fundamentally unreliable: real capacity differences of 12-25% exist within every model, but BMS SOH fails to track them, with correlations ranging from \r{ho} = 0.10 (non-significant) to \r{ho} = 0.62 only under restrictive filtering, while 384 vehicles do not expose SOH at all. A manufacturer-independent electrochemical marker achieves 74-89% degradation classification accuracy across all platforms without requiring BMS data, and a controlled laboratory validation on cells identical to those in the fleet confirms that partial-voltage-window charge measurements track reference capacity with \r{ho} > 0.80 across all 60 voltage windows (p < 0.001). These findings reveal a structural information asymmetry with direct implications for the EU Battery Regulation's 2027 SOH transparency mandate, California's Advanced Clean Cars (ACC) II durability requirements, warranty enforcement, used-vehicle valuation, right-to-repair legislation, and second-life battery markets.
MGTANet: Encoding Sequential LiDAR Points Using Long Short-Term Motion-Guided Temporal Attention for 3D Object Detection
Dec 21, 2022Most scanning LiDAR sensors generate a sequence of point clouds in real-time. While conventional 3D object detectors use a set of unordered LiDAR points acquired over a fixed time interval, recent studies have revealed that substantial performance improvement can be achieved by exploiting the spatio-temporal context present in a sequence of LiDAR point sets. In this paper, we propose a novel 3D object detection architecture, which can encode LiDAR point cloud sequences acquired by multiple successive scans. The encoding process of the point cloud sequence is performed on two different time scales. We first design a short-term motion-aware voxel encoding that captures the short-term temporal changes of point clouds driven by the motion of objects in each voxel. We also propose long-term motion-guided bird's eye view (BEV) feature enhancement that adaptively aligns and aggregates the BEV feature maps obtained by the short-term voxel encoding by utilizing the dynamic motion context inferred from the sequence of the feature maps. The experiments conducted on the public nuScenes benchmark demonstrate that the proposed 3D object detector offers significant improvements in performance compared to the baseline methods and that it sets a state-of-the-art performance for certain 3D object detection categories. Code is available at https://github.com/HYjhkoh/MGTANet.git
D-Align: Dual Query Co-attention Network for 3D Object Detection Based on Multi-frame Point Cloud Sequence
Sep 30, 2022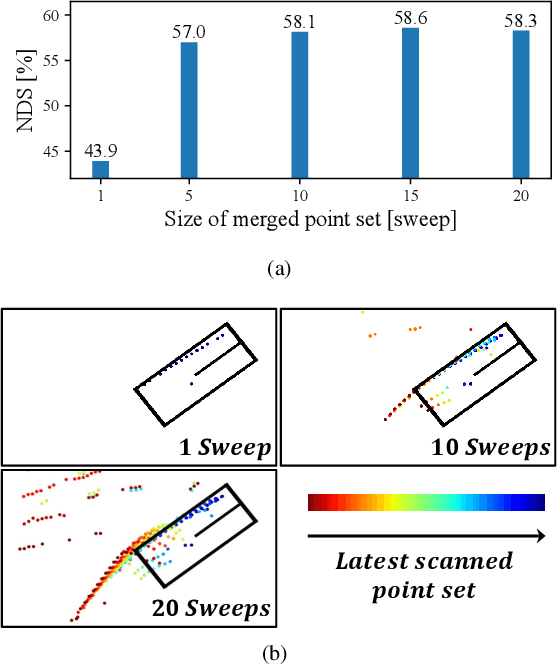
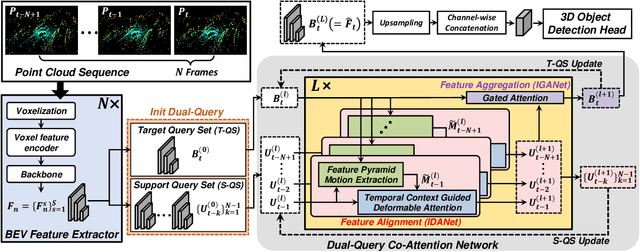
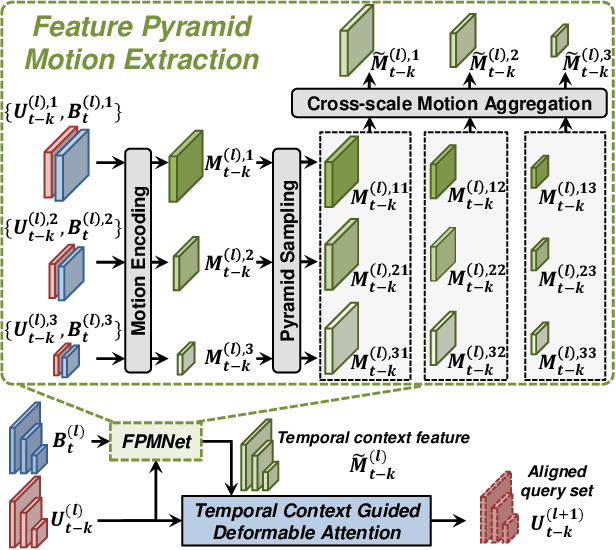
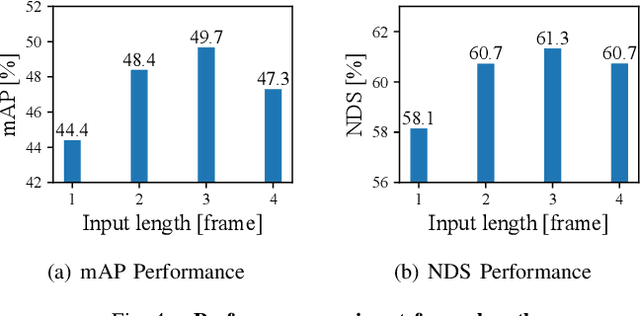
LiDAR sensors are widely used for 3D object detection in various mobile robotics applications. LiDAR sensors continuously generate point cloud data in real-time. Conventional 3D object detectors detect objects using a set of points acquired over a fixed duration. However, recent studies have shown that the performance of object detection can be further enhanced by utilizing spatio-temporal information obtained from point cloud sequences. In this paper, we propose a new 3D object detector, named D-Align, which can effectively produce strong bird's-eye-view (BEV) features by aligning and aggregating the features obtained from a sequence of point sets. The proposed method includes a novel dual-query co-attention network that uses two types of queries, including target query set (T-QS) and support query set (S-QS), to update the features of target and support frames, respectively. D-Align aligns S-QS to T-QS based on the temporal context features extracted from the adjacent feature maps and then aggregates S-QS with T-QS using a gated attention mechanism. The dual queries are updated through multiple attention layers to progressively enhance the target frame features used to produce the detection results. Our experiments on the nuScenes dataset show that the proposed D-Align method greatly improved the performance of a single frame-based baseline method and significantly outperformed the latest 3D object detectors.