 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKorean Online Hate Speech Dataset for Multilabel Classification: How Can Social Science Improve Dataset on Hate Speech?
Apr 08, 2022


We suggest a multilabel Korean online hate speech dataset that covers seven categories of hate speech: (1) Race and Nationality, (2) Religion, (3) Regionalism, (4) Ageism, (5) Misogyny, (6) Sexual Minorities, and (7) Male. Our 35K dataset consists of 24K online comments with Krippendorff's Alpha label accordance of .713, 2.2K neutral sentences from Wikipedia, 1.7K additionally labeled sentences generated by the Human-in-the-Loop procedure and rule-generated 7.1K neutral sentences. The base model with 24K initial dataset achieved the accuracy of LRAP .892, but improved to .919 after being combined with 11K additional data. Unlike the conventional binary hate and non-hate dichotomy approach, we designed a dataset considering both the cultural and linguistic context to overcome the limitations of western culture-based English texts. Thus, this paper is not only limited to presenting a local hate speech dataset but extends as a manual for building a more generalized hate speech dataset with diverse cultural backgrounds based on social science perspectives.
BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection
May 26, 2020

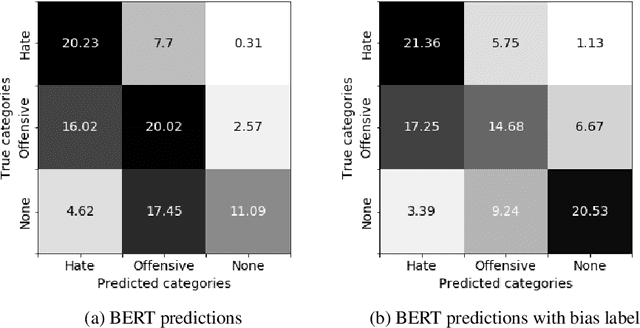
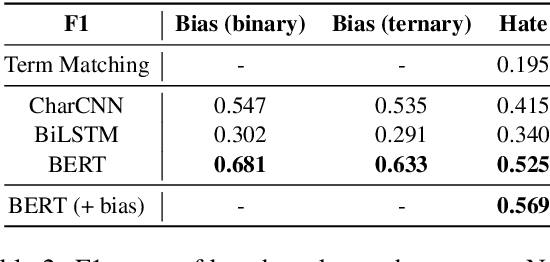
Toxic comments in online platforms are an unavoidable social issue under the cloak of anonymity. Hate speech detection has been actively done for languages such as English, German, or Italian, where manually labeled corpus has been released. In this work, we first present 9.4K manually labeled entertainment news comments for identifying Korean toxic speech, collected from a widely used online news platform in Korea. The comments are annotated regarding social bias and hate speech since both aspects are correlated. The inter-annotator agreement Krippendorff's alpha score is 0.492 and 0.496, respectively. We provide benchmarks using CharCNN, BiLSTM, and BERT, where BERT achieves the highest score on all tasks. The models generally display better performance on bias identification, since the hate speech detection is a more subjective issue. Additionally, when BERT is trained with bias label for hate speech detection, the prediction score increases, implying that bias and hate are intertwined. We make our dataset publicly available and open competitions with the corpus and benchmarks.