 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHold the Suspect! : An Analysis on Media Framing of Itaewon Halloween Crowd Crush
Apr 23, 2023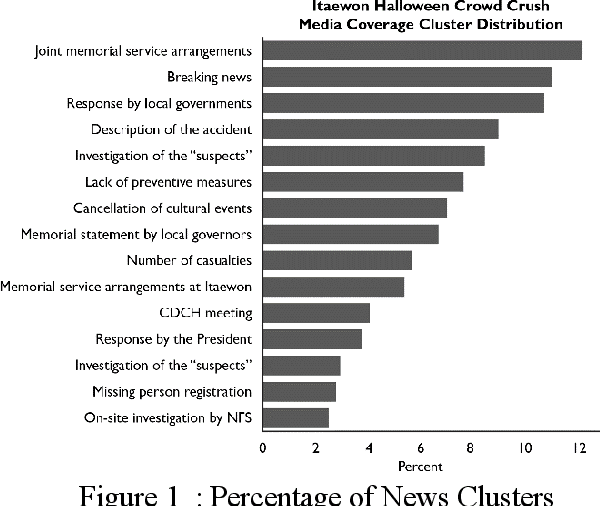
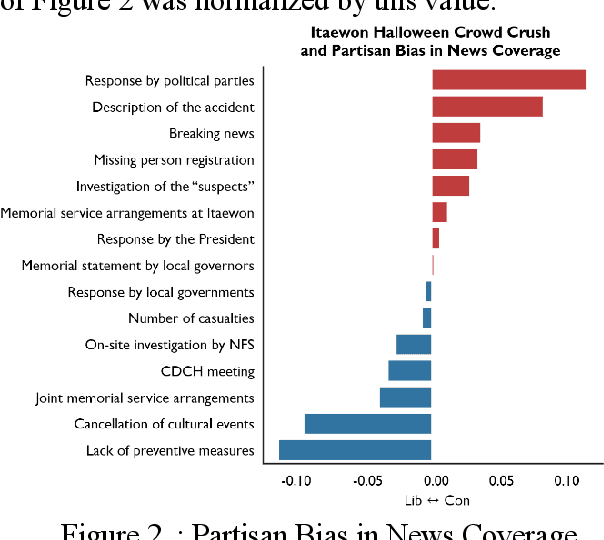
Based on the 10.9K articles from top 40 news providers of South Korea, this paper analyzed the media framing of Itaewon Halloween Crowd Crush during the first 72 hours after the incident. By adopting word-vector embedding and clustering, we figured out that conservative media focused on political parties' responses and the suspect's identity while the liberal media covered the responsibility of the government and possible unequal spillover effect on the low-income industry workers. Although the social tragedy was not directly connected to institutional politics, the media clearly exhibited political bias in the coverage process.
Suffering from Vaccines or from Government? : Partisan Bias in COVID-19 Vaccine Adverse Events Coverage
Nov 19, 2022Vaccine adverse events have been presumed to be a relatively objective measure that is immune to political polarization. The real-world data, however, shows the correlation between presidential disapproval ratings and the subjective severity of adverse events. This paper investigates the partisan bias in COVID vaccine adverse events coverage with language models that can classify the topic of vaccine-related articles and the political disposition of news comments. Based on 90K news articles from 52 major newspaper companies, we found that conservative media are inclined to report adverse events more frequently than their liberal counterparts, while the coverage itself was statistically uncorrelated with the severity of real-world adverse events. The users who support the conservative opposing party were more likely to write the popular comments from 2.3K random sampled articles on news platforms. This research implies that bipartisanship can still play a significant role in forming public opinion on the COVID vaccine even after the majority of the population's vaccination
Korean Online Hate Speech Dataset for Multilabel Classification: How Can Social Science Improve Dataset on Hate Speech?
Apr 08, 2022


We suggest a multilabel Korean online hate speech dataset that covers seven categories of hate speech: (1) Race and Nationality, (2) Religion, (3) Regionalism, (4) Ageism, (5) Misogyny, (6) Sexual Minorities, and (7) Male. Our 35K dataset consists of 24K online comments with Krippendorff's Alpha label accordance of .713, 2.2K neutral sentences from Wikipedia, 1.7K additionally labeled sentences generated by the Human-in-the-Loop procedure and rule-generated 7.1K neutral sentences. The base model with 24K initial dataset achieved the accuracy of LRAP .892, but improved to .919 after being combined with 11K additional data. Unlike the conventional binary hate and non-hate dichotomy approach, we designed a dataset considering both the cultural and linguistic context to overcome the limitations of western culture-based English texts. Thus, this paper is not only limited to presenting a local hate speech dataset but extends as a manual for building a more generalized hate speech dataset with diverse cultural backgrounds based on social science perspectives.