 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPPFLChain: A Privacy Protection Distributed Artificial-Intelligence Architecture Based on Federated Learning and Consortium Blockchain
Jun 26, 2022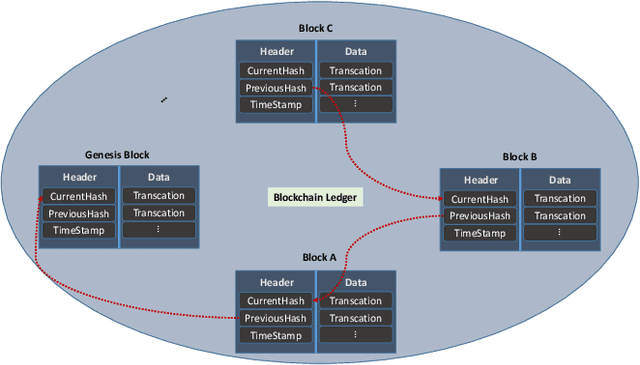
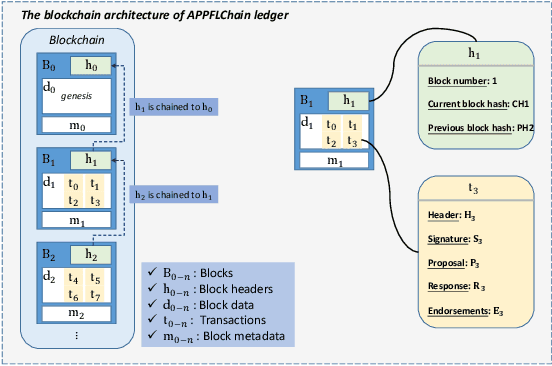
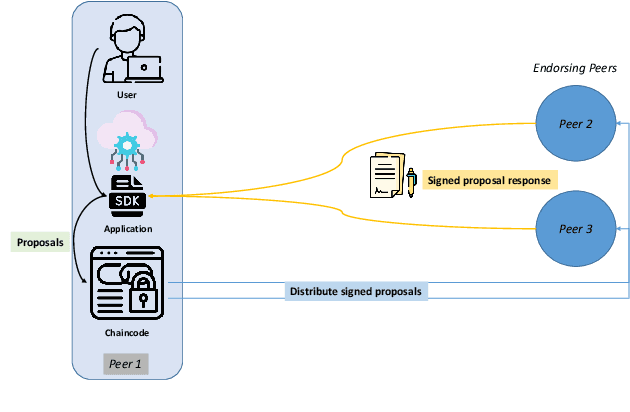
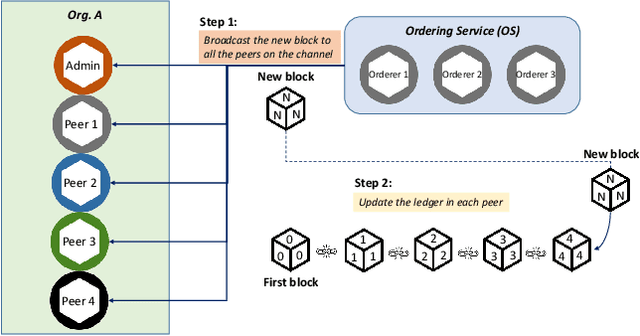
Recent research in Internet of things has been widely applied for industrial practices, fostering the exponential growth of data and connected devices. Henceforth, data-driven AI models would be accessed by different parties through certain data-sharing policies. However, most of the current training procedures rely on the centralized data-collection strategy and a single computational server. However, such a centralized scheme may lead to many issues. Customer data stored in a centralized database may be tampered with so the provenance and authenticity of data cannot be justified. Once the aforementioned security concerns occur, the credibility of the trained AI models would be questionable and even unfavorable outcomes might be produced at the test stage. Lately, blockchain and AI, the two core technologies in Industry 4.0 and Web 3.0, have been explored to facilitate the decentralized AI training strategy. To serve on this very purpose, we propose a new system architecture called APPFLChain, namely an integrated architecture of a Hyperledger Fabric-based blockchain and a federated-learning paradigm. Our proposed new system allows different parties to jointly train AI models and their customers or stakeholders are connected by a consortium blockchain-based network. Our new system can maintain a high degree of security and privacy as users do not need to share sensitive personal information to the server. For numerical evaluation, we simulate a real-world scenario to illustrate the whole operational process of APPFLChain. Simulation results show that taking advantage of the characteristics of consortium blockchain and federated learning, APPFLChain can demonstrate favorable properties including untamperability, traceability, privacy protection, and reliable decision-making.
Knowledge Distillation with Representative Teacher Keys Based on Attention Mechanism for Image Classification Model Compression
Jun 26, 2022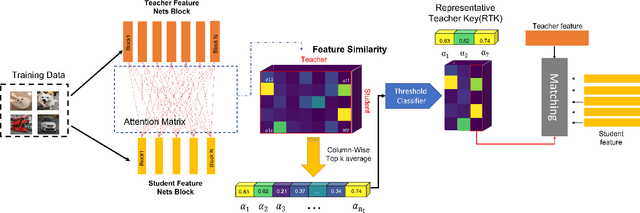
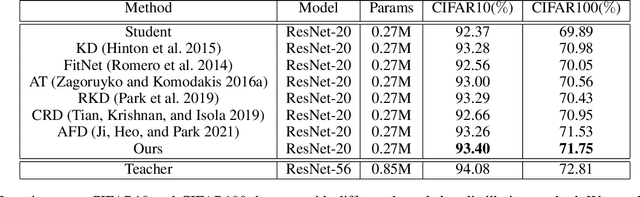
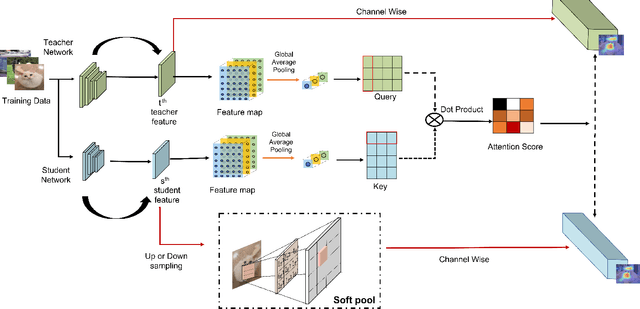
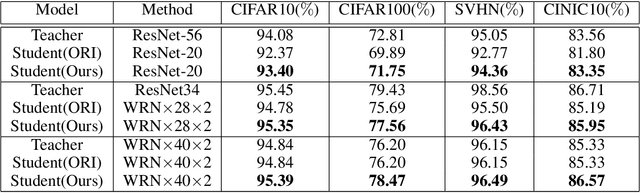
With the improvement of AI chips (e.g., GPU, TPU, and NPU) and the fast development of internet of things (IoTs), some powerful deep neural networks (DNNs) are usually composed of millions or even hundreds of millions of parameters, which may not be suitable to be directly deployed on low computation and low capacity units (e.g., edge devices). Recently, knowledge distillation (KD) has been recognized as one of the effective method of model compression to decrease the model parameters. The main concept of KD is to extract useful information from the feature maps of a large model (i.e., teacher model) as a reference to successfully train a small model (i.e., student model) which model size is much smaller than the teacher one. Although many KD-based methods have been proposed to utilize the information from the feature maps of intermediate layers in teacher model, however, most of them did not consider the similarity of feature maps between teacher model and student model, which may let student model learn useless information. Inspired by attention mechanism, we propose a novel KD method called representative teacher key (RTK) that not only consider the similarity of feature maps but also filter out the useless information to improve the performance of the target student model. In the experiments, we validate our proposed method with several backbone networks (e.g., ResNet and WideResNet) and datasets (e.g., CIFAR10, CIFAR100, SVHN, and CINIC10). The results show that our proposed RTK can effectively improve the classification accuracy of the state-of-the-art attention-based KD method.
Multimodal Deception Detection in Videos via Analyzing Emotional State-based Feature
Apr 16, 2021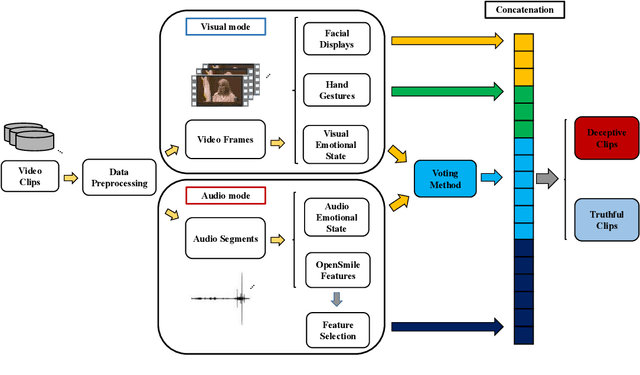
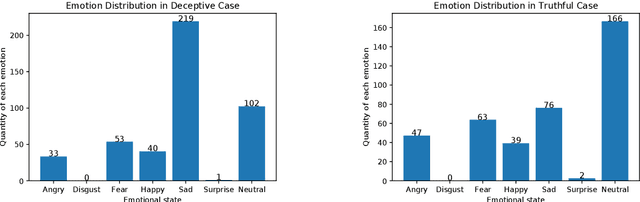
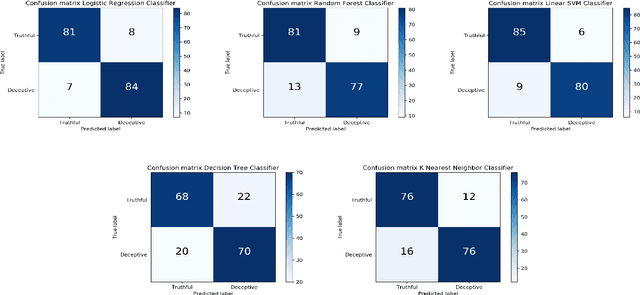
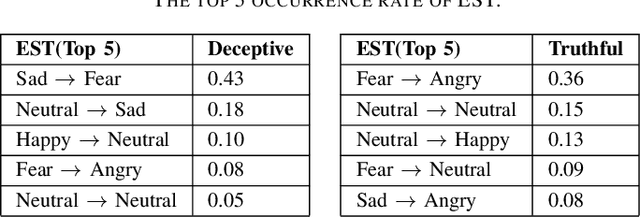
Deception detection is an important task that has been a hot research topic due to its potential applications. It can be applied to many areas from national security (e.g, airport security, jurisprudence, and law enforcement) to real-life applications (e.g., business and computer vision). However, some critical problems still exist and worth more investigation. One of the major challenges is the data scarcity problem. Until now, only one multimodal benchmark dataset on deception detection has been published, which contains 121 video clips for deception detection (61 for deceptive class and 60 for truthful class). This amount of data is hard to drive deep neural network-based methods. Hence, they often suffered from the overfitting problem and the bad generalization ability. Also, the ground truth data contains some unusable frames for many factors including the face is too small to be recognized the facial expression, face is covered by text, file corruption, etc. However, most of the literature did not consider these problems. In this paper, we design a series of data preprocessing methods to deal with the problem first. Then, we propose a multimodal deception detection framework to construct our novel emotional state-based feature and used open toolkit openSMILE to extract the features from audio modality. A voting scheme is also designed to combine the emotional state information obtained from both visual modality and audio modality. Finally, the novel emotion state transformation (EST) feature is determined by our algorithm. The critical analysis and comparison of the proposed methods with the state-of-the-art multimodal method are showed that the overall performance has a great improvement of accuracy from 84.16% to 91.67% and ROC-AUC from 0.9211 to 0.9244.