 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deception Detection in Videos via Analyzing Emotional State-based Feature
Paper and Code
Apr 16, 2021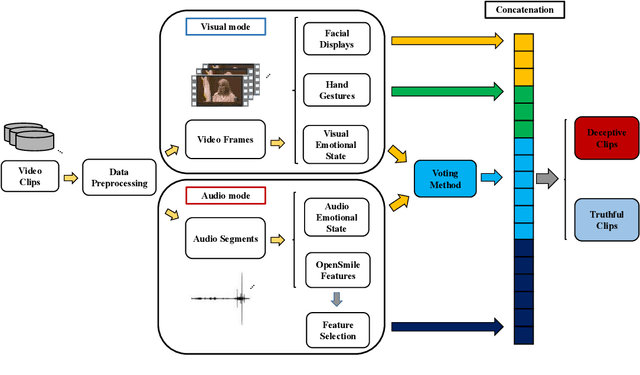
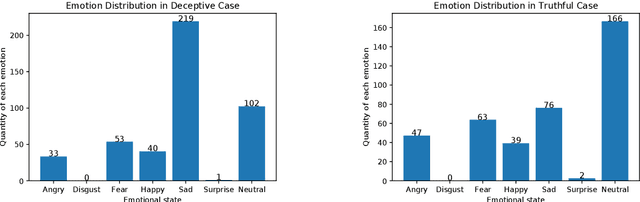
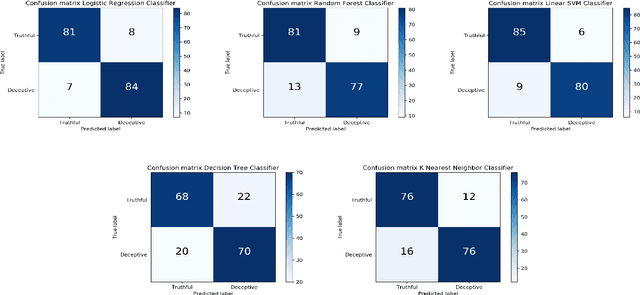
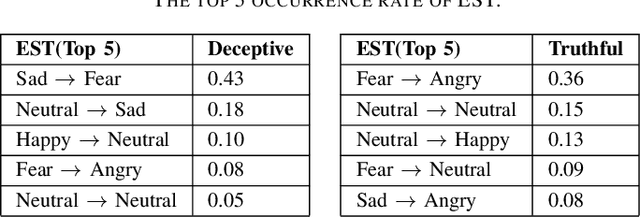
Deception detection is an important task that has been a hot research topic due to its potential applications. It can be applied to many areas from national security (e.g, airport security, jurisprudence, and law enforcement) to real-life applications (e.g., business and computer vision). However, some critical problems still exist and worth more investigation. One of the major challenges is the data scarcity problem. Until now, only one multimodal benchmark dataset on deception detection has been published, which contains 121 video clips for deception detection (61 for deceptive class and 60 for truthful class). This amount of data is hard to drive deep neural network-based methods. Hence, they often suffered from the overfitting problem and the bad generalization ability. Also, the ground truth data contains some unusable frames for many factors including the face is too small to be recognized the facial expression, face is covered by text, file corruption, etc. However, most of the literature did not consider these problems. In this paper, we design a series of data preprocessing methods to deal with the problem first. Then, we propose a multimodal deception detection framework to construct our novel emotional state-based feature and used open toolkit openSMILE to extract the features from audio modality. A voting scheme is also designed to combine the emotional state information obtained from both visual modality and audio modality. Finally, the novel emotion state transformation (EST) feature is determined by our algorithm. The critical analysis and comparison of the proposed methods with the state-of-the-art multimodal method are showed that the overall performance has a great improvement of accuracy from 84.16% to 91.67% and ROC-AUC from 0.9211 to 0.9244.