 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation with Representative Teacher Keys Based on Attention Mechanism for Image Classification Model Compression
Jun 26, 2022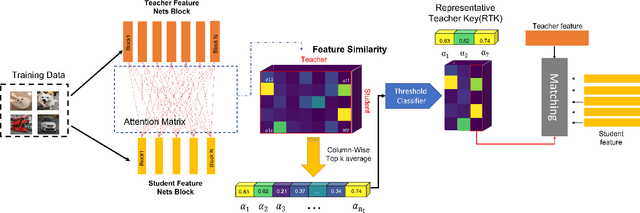
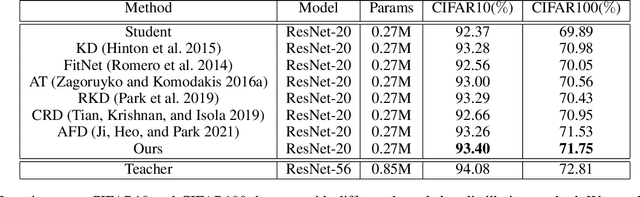
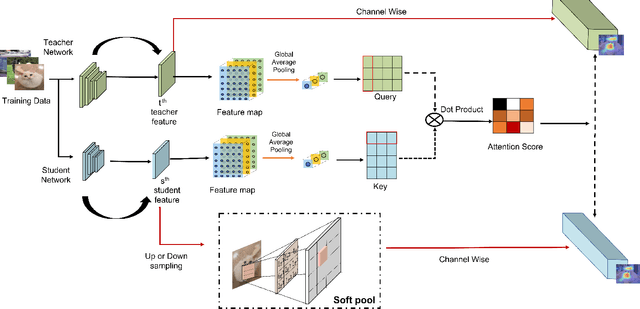
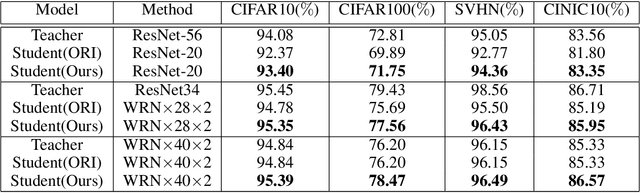
With the improvement of AI chips (e.g., GPU, TPU, and NPU) and the fast development of internet of things (IoTs), some powerful deep neural networks (DNNs) are usually composed of millions or even hundreds of millions of parameters, which may not be suitable to be directly deployed on low computation and low capacity units (e.g., edge devices). Recently, knowledge distillation (KD) has been recognized as one of the effective method of model compression to decrease the model parameters. The main concept of KD is to extract useful information from the feature maps of a large model (i.e., teacher model) as a reference to successfully train a small model (i.e., student model) which model size is much smaller than the teacher one. Although many KD-based methods have been proposed to utilize the information from the feature maps of intermediate layers in teacher model, however, most of them did not consider the similarity of feature maps between teacher model and student model, which may let student model learn useless information. Inspired by attention mechanism, we propose a novel KD method called representative teacher key (RTK) that not only consider the similarity of feature maps but also filter out the useless information to improve the performance of the target student model. In the experiments, we validate our proposed method with several backbone networks (e.g., ResNet and WideResNet) and datasets (e.g., CIFAR10, CIFAR100, SVHN, and CINIC10). The results show that our proposed RTK can effectively improve the classification accuracy of the state-of-the-art attention-based KD method.