 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Community Detection in Networks: A Comparative Analysis of Local Metrics and Hierarchical Algorithms
Aug 17, 2024



The analysis and detection of communities in network structures are becoming increasingly relevant for understanding social behavior. One of the principal challenges in this field is the complexity of existing algorithms. The Girvan-Newman algorithm, which uses the betweenness metric as a measure of node similarity, is one of the most representative algorithms in this area. This study employs the same method to evaluate the relevance of using local similarity metrics for community detection. A series of local metrics were tested on a set of networks constructed using the Girvan-Newman basic algorithm. The efficacy of these metrics was evaluated by applying the base algorithm to several real networks with varying community sizes, using modularity and NMI. The results indicate that approaches based on local similarity metrics have significant potential for community detection.
On the use of local structural properties for improving the efficiency of hierarchical community detection methods
Sep 15, 2020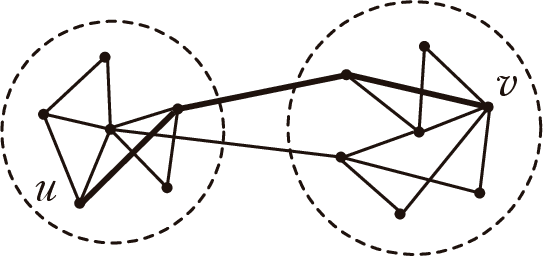

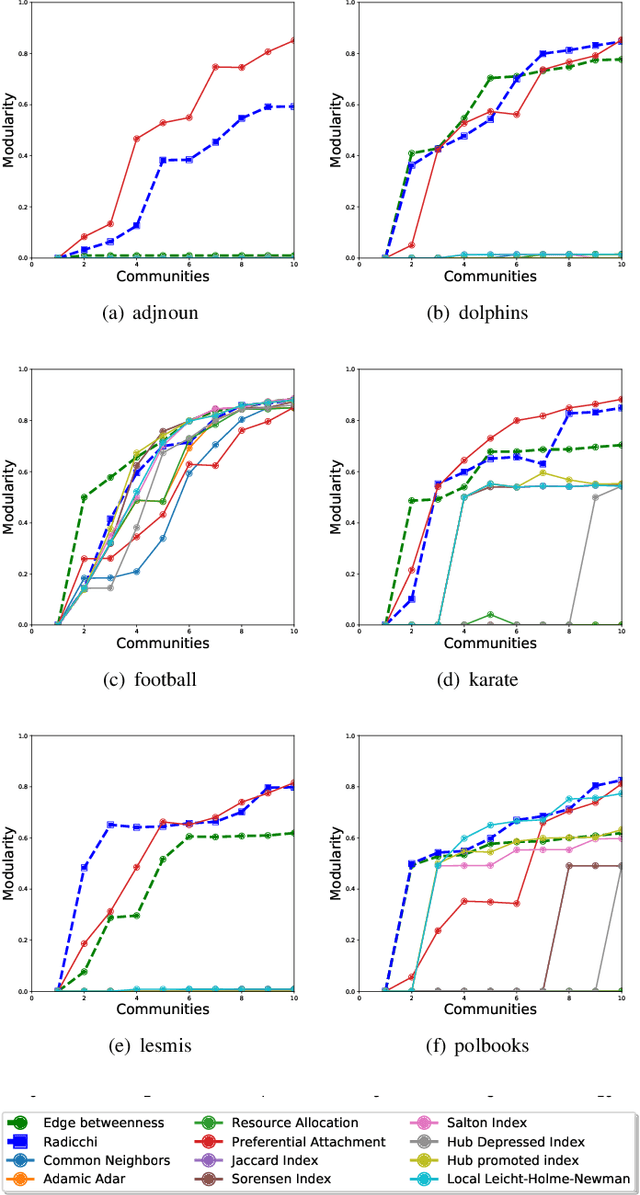

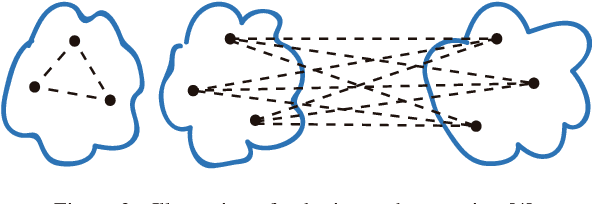
Community detection is a fundamental problem in the analysis of complex networks. It is the analogue of clustering in network data mining. Within community detection methods, hierarchical algorithms are popular. However, their iterative nature and the need to recompute the structural properties used to split the network (i.e. edge betweenness in Girvan and Newman's algorithm), make them unsuitable for large network data sets. In this paper, we study how local structural network properties can be used as proxies to improve the efficiency of hierarchical community detection while, at the same time, achieving competitive results in terms of modularity. In particular, we study the potential use of the structural properties commonly used to perform local link prediction, a supervised learning problem where community structure is relevant, as nodes are prone to establish new links with other nodes within their communities. In addition, we check the performance impact of network pruning heuristics as an ancillary tactic to make hierarchical community detection more efficient
Evaluation Metrics for Unsupervised Learning Algorithms
May 23, 2019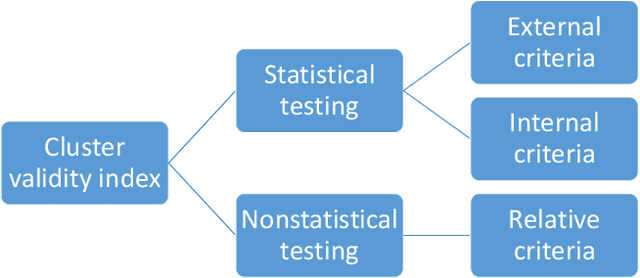
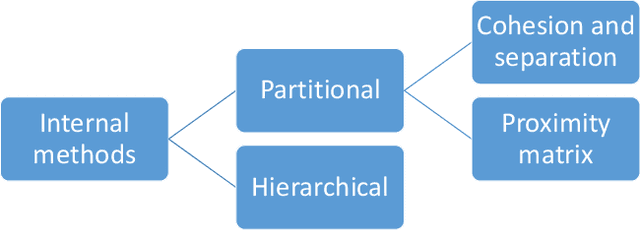
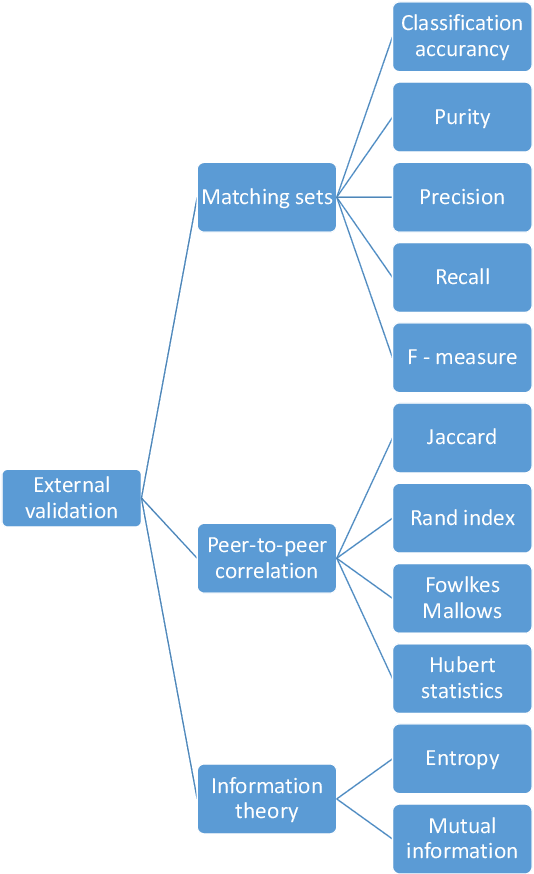
Determining the quality of the results obtained by clustering techniques is a key issue in unsupervised machine learning. Many authors have discussed the desirable features of good clustering algorithms. However, Jon Kleinberg established an impossibility theorem for clustering. As a consequence, a wealth of studies have proposed techniques to evaluate the quality of clustering results depending on the characteristics of the clustering problem and the algorithmic technique employed to cluster data.