 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDL101 Neural Network Outputs and Loss Functions
Nov 07, 2025
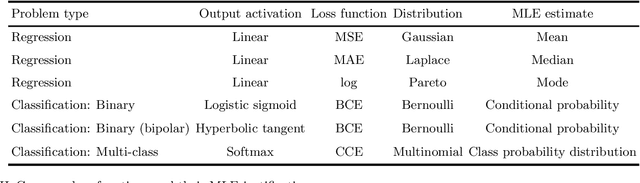
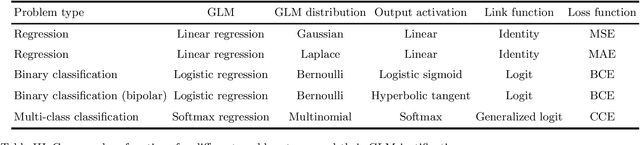
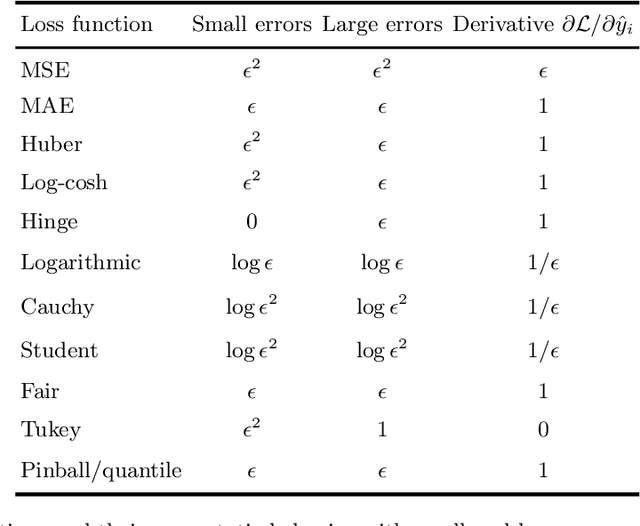
The loss function used to train a neural network is strongly connected to its output layer from a statistical point of view. This technical report analyzes common activation functions for a neural network output layer, like linear, sigmoid, ReLU, and softmax, detailing their mathematical properties and their appropriate use cases. A strong statistical justification exists for the selection of the suitable loss function for training a deep learning model. This report connects common loss functions such as Mean Squared Error (MSE), Mean Absolute Error (MAE), and various Cross-Entropy losses to the statistical principle of Maximum Likelihood Estimation (MLE). Choosing a specific loss function is equivalent to assuming a specific probability distribution for the model output, highlighting the link between these functions and the Generalized Linear Models (GLMs) that underlie network output layers. Additional scenarios of practical interest are also considered, such as alternative output encodings, constrained outputs, and distributions with heavy tails.
Differential Privacy in Machine Learning: From Symbolic AI to LLMs
Jun 13, 2025Machine learning models should not reveal particular information that is not otherwise accessible. Differential privacy provides a formal framework to mitigate privacy risks by ensuring that the inclusion or exclusion of any single data point does not significantly alter the output of an algorithm, thus limiting the exposure of private information. This survey paper explores the foundational definitions of differential privacy, reviews its original formulations and tracing its evolution through key research contributions. It then provides an in-depth examination of how DP has been integrated into machine learning models, analyzing existing proposals and methods to preserve privacy when training ML models. Finally, it describes how DP-based ML techniques can be evaluated in practice. %Finally, it discusses the broader implications of DP, highlighting its potential for public benefit, its real-world applications, and the challenges it faces, including vulnerabilities to adversarial attacks. By offering a comprehensive overview of differential privacy in machine learning, this work aims to contribute to the ongoing development of secure and responsible AI systems.
LLM Security: Vulnerabilities, Attacks, Defenses, and Countermeasures
May 02, 2025
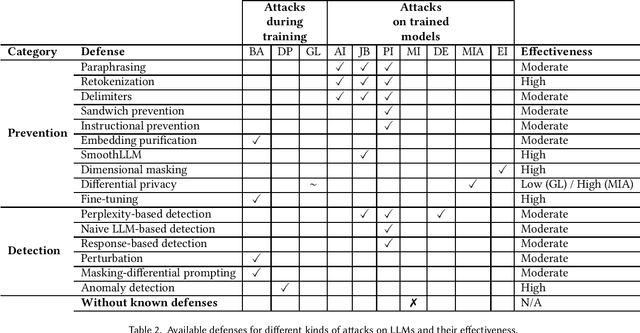
As large language models (LLMs) continue to evolve, it is critical to assess the security threats and vulnerabilities that may arise both during their training phase and after models have been deployed. This survey seeks to define and categorize the various attacks targeting LLMs, distinguishing between those that occur during the training phase and those that affect already trained models. A thorough analysis of these attacks is presented, alongside an exploration of defense mechanisms designed to mitigate such threats. Defenses are classified into two primary categories: prevention-based and detection-based defenses. Furthermore, our survey summarizes possible attacks and their corresponding defense strategies. It also provides an evaluation of the effectiveness of the known defense mechanisms for the different security threats. Our survey aims to offer a structured framework for securing LLMs, while also identifying areas that require further research to improve and strengthen defenses against emerging security challenges.
Differential Privacy Regularization: Protecting Training Data Through Loss Function Regularization
Sep 25, 2024Training machine learning models based on neural networks requires large datasets, which may contain sensitive information. The models, however, should not expose private information from these datasets. Differentially private SGD [DP-SGD] requires the modification of the standard stochastic gradient descent [SGD] algorithm for training new models. In this short paper, a novel regularization strategy is proposed to achieve the same goal in a more efficient manner.
Enhancing Community Detection in Networks: A Comparative Analysis of Local Metrics and Hierarchical Algorithms
Aug 17, 2024



The analysis and detection of communities in network structures are becoming increasingly relevant for understanding social behavior. One of the principal challenges in this field is the complexity of existing algorithms. The Girvan-Newman algorithm, which uses the betweenness metric as a measure of node similarity, is one of the most representative algorithms in this area. This study employs the same method to evaluate the relevance of using local similarity metrics for community detection. A series of local metrics were tested on a set of networks constructed using the Girvan-Newman basic algorithm. The efficacy of these metrics was evaluated by applying the base algorithm to several real networks with varying community sizes, using modularity and NMI. The results indicate that approaches based on local similarity metrics have significant potential for community detection.
On the use of local structural properties for improving the efficiency of hierarchical community detection methods
Sep 15, 2020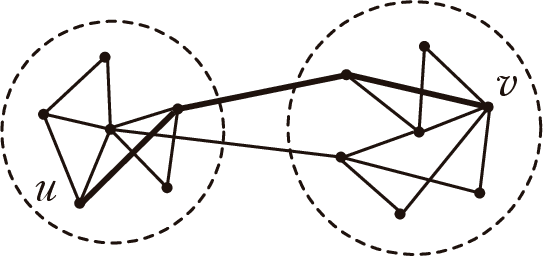

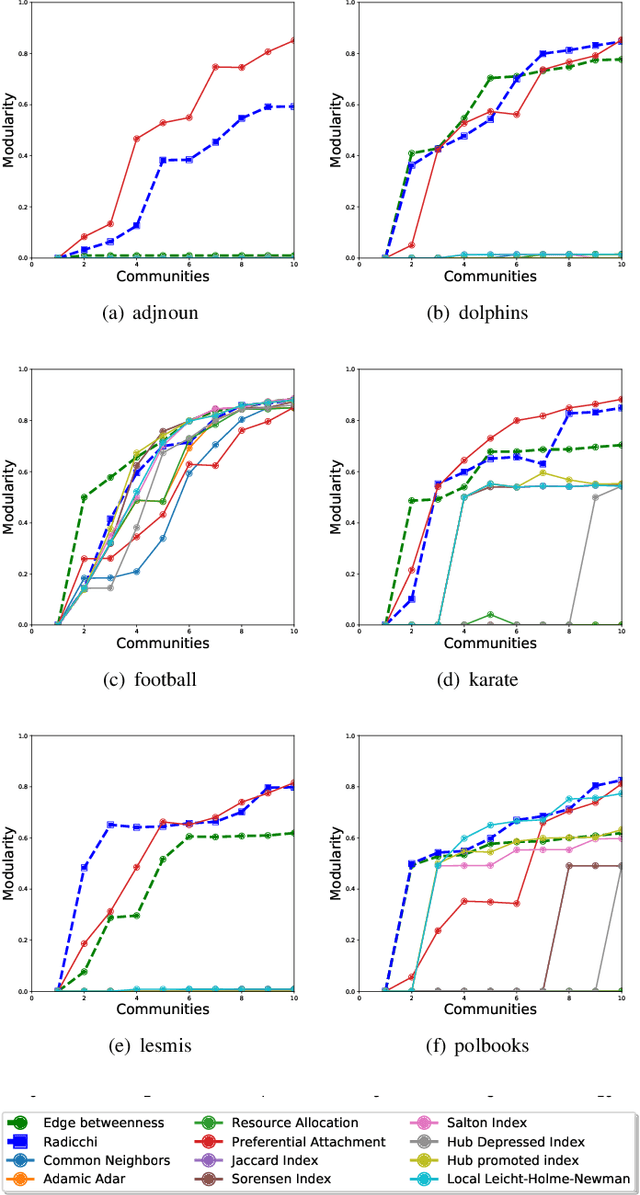

Community detection is a fundamental problem in the analysis of complex networks. It is the analogue of clustering in network data mining. Within community detection methods, hierarchical algorithms are popular. However, their iterative nature and the need to recompute the structural properties used to split the network (i.e. edge betweenness in Girvan and Newman's algorithm), make them unsuitable for large network data sets. In this paper, we study how local structural network properties can be used as proxies to improve the efficiency of hierarchical community detection while, at the same time, achieving competitive results in terms of modularity. In particular, we study the potential use of the structural properties commonly used to perform local link prediction, a supervised learning problem where community structure is relevant, as nodes are prone to establish new links with other nodes within their communities. In addition, we check the performance impact of network pruning heuristics as an ancillary tactic to make hierarchical community detection more efficient
Evaluation Metrics for Unsupervised Learning Algorithms
May 23, 2019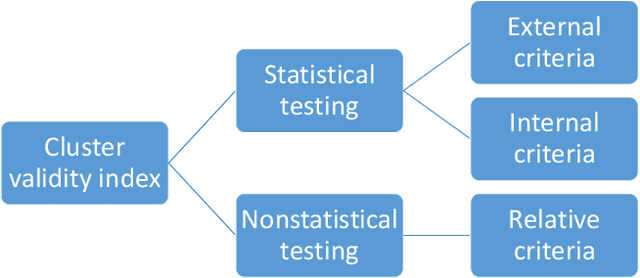
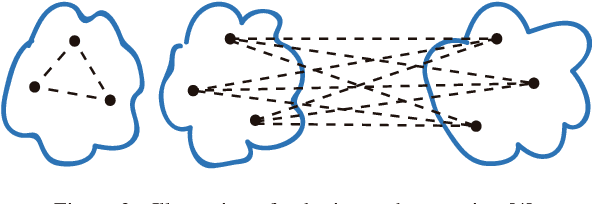
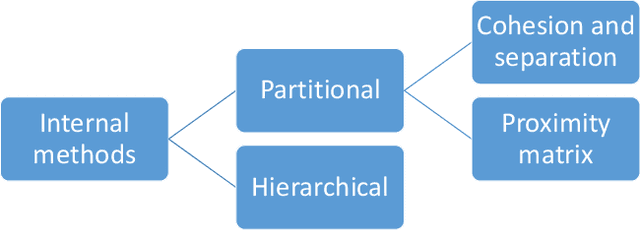
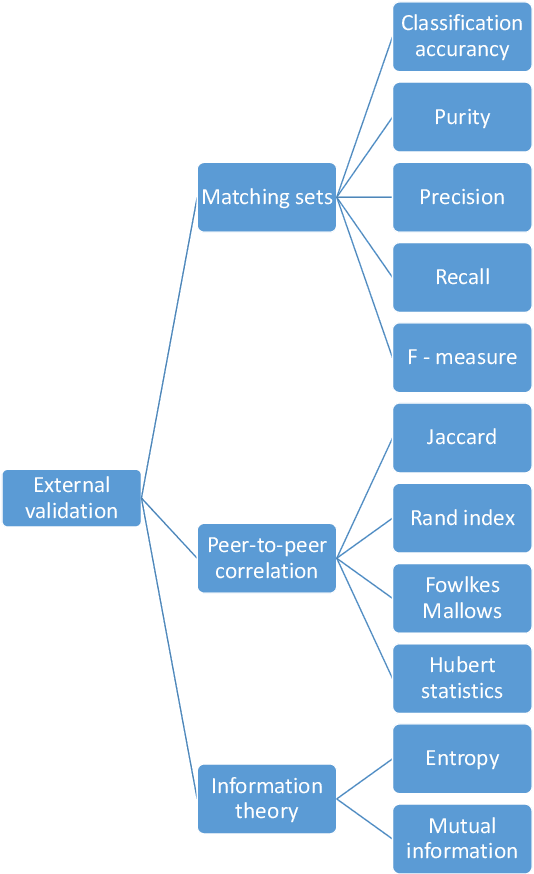
Determining the quality of the results obtained by clustering techniques is a key issue in unsupervised machine learning. Many authors have discussed the desirable features of good clustering algorithms. However, Jon Kleinberg established an impossibility theorem for clustering. As a consequence, a wealth of studies have proposed techniques to evaluate the quality of clustering results depending on the characteristics of the clustering problem and the algorithmic technique employed to cluster data.
The NOESIS Network-Oriented Exploration, Simulation, and Induction System
Jun 23, 2017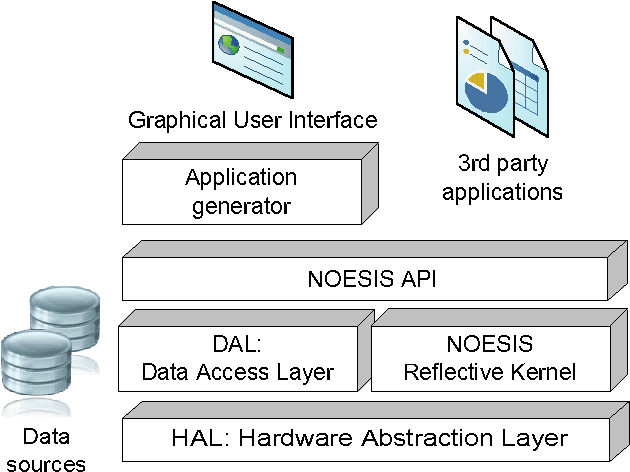
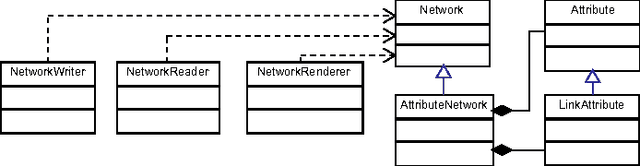
Network data mining has become an important area of study due to the large number of problems it can be applied to. This paper presents NOESIS, an open source framework for network data mining that provides a large collection of network analysis techniques, including the analysis of network structural properties, community detection methods, link scoring, and link prediction, as well as network visualization algorithms. It also features a complete stand-alone graphical user interface that facilitates the use of all these techniques. The NOESIS framework has been designed using solid object-oriented design principles and structured parallel programming. As a lightweight library with minimal external dependencies and a permissive software license, NOESIS can be incorporated into other software projects. Released under a BSD license, it is available from http://noesis.ikor.org.
A Model-Driven Probabilistic Parser Generator
May 14, 2012
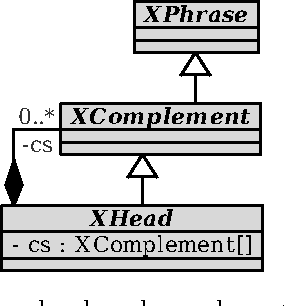

Existing probabilistic scanners and parsers impose hard constraints on the way lexical and syntactic ambiguities can be resolved. Furthermore, traditional grammar-based parsing tools are limited in the mechanisms they allow for taking context into account. In this paper, we propose a model-driven tool that allows for statistical language models with arbitrary probability estimators. Our work on model-driven probabilistic parsing is built on top of ModelCC, a model-based parser generator, and enables the probabilistic interpretation and resolution of anaphoric, cataphoric, and recursive references in the disambiguation of abstract syntax graphs. In order to prove the expression power of ModelCC, we describe the design of a general-purpose natural language parser.
A Lexical Analysis Tool with Ambiguity Support
Feb 29, 2012


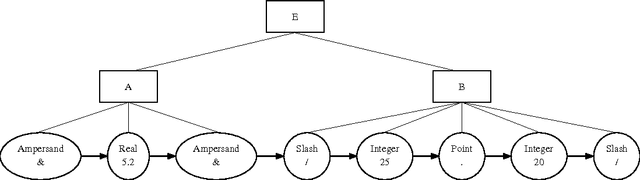
Lexical ambiguities naturally arise in languages. We present Lamb, a lexical analyzer that produces a lexical analysis graph describing all the possible sequences of tokens that can be found within the input string. Parsers can process such lexical analysis graphs and discard any sequence of tokens that does not produce a valid syntactic sentence, therefore performing, together with Lamb, a context-sensitive lexical analysis in lexically-ambiguous language specifications.