 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Alignment and Uniformity for Contrastive Learning with Continuous Proxy Labels
Nov 10, 2021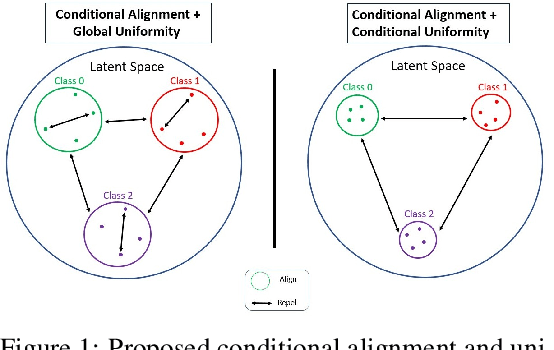
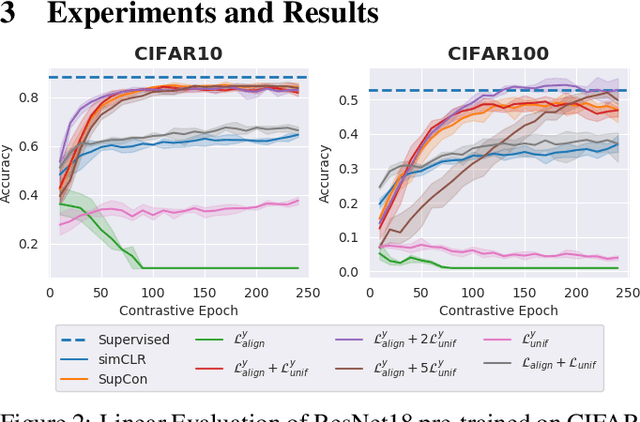
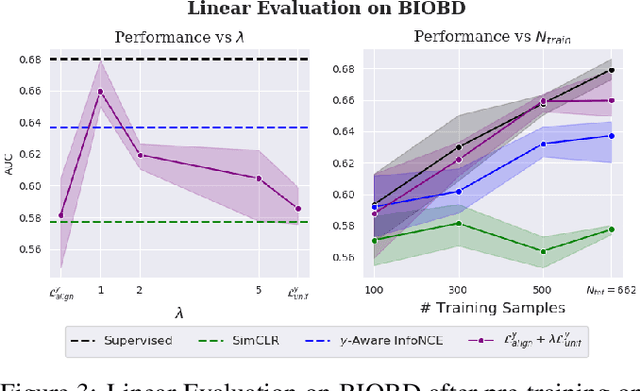
Contrastive Learning has shown impressive results on natural and medical images, without requiring annotated data. However, a particularity of medical images is the availability of meta-data (such as age or sex) that can be exploited for learning representations. Here, we show that the recently proposed contrastive y-Aware InfoNCE loss, that integrates multi-dimensional meta-data, asymptotically optimizes two properties: conditional alignment and global uniformity. Similarly to [Wang, 2020], conditional alignment means that similar samples should have similar features, but conditionally on the meta-data. Instead, global uniformity means that the (normalized) features should be uniformly distributed on the unit hyper-sphere, independently of the meta-data. Here, we propose to define conditional uniformity, relying on the meta-data, that repel only samples with dissimilar meta-data. We show that direct optimization of both conditional alignment and uniformity improves the representations, in terms of linear evaluation, on both CIFAR-100 and a brain MRI dataset.
Contrastive Learning with Continuous Proxy Meta-Data for 3D MRI Classification
Jun 16, 2021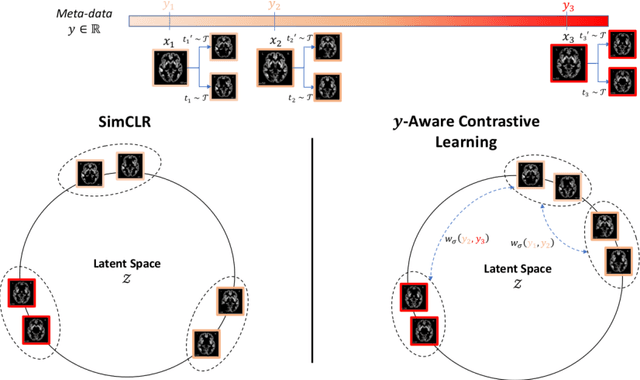
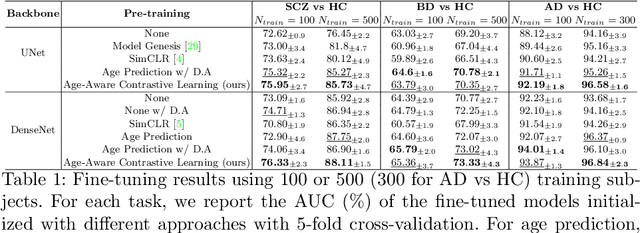
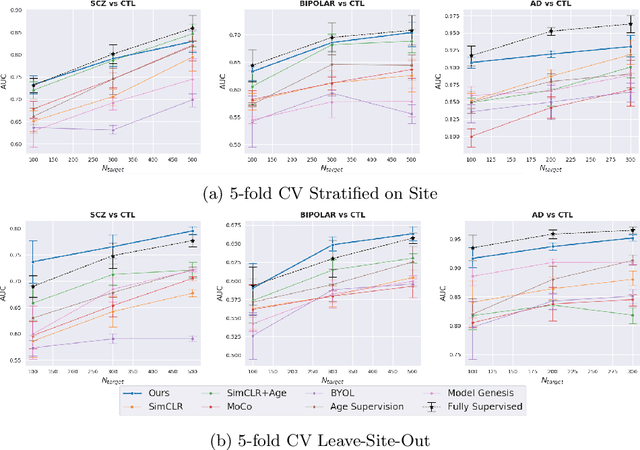
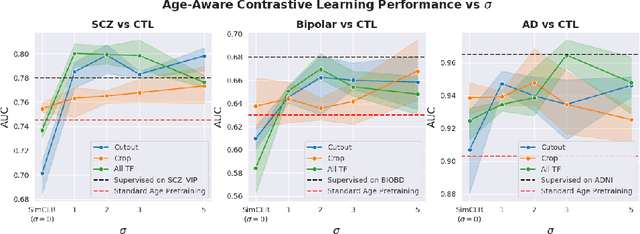
Traditional supervised learning with deep neural networks requires a tremendous amount of labelled data to converge to a good solution. For 3D medical images, it is often impractical to build a large homogeneous annotated dataset for a specific pathology. Self-supervised methods offer a new way to learn a representation of the images in an unsupervised manner with a neural network. In particular, contrastive learning has shown great promises by (almost) matching the performance of fully-supervised CNN on vision tasks. Nonetheless, this method does not take advantage of available meta-data, such as participant's age, viewed as prior knowledge. Here, we propose to leverage continuous proxy metadata, in the contrastive learning framework, by introducing a new loss called y-Aware InfoNCE loss. Specifically, we improve the positive sampling during pre-training by adding more positive examples with similar proxy meta-data with the anchor, assuming they share similar discriminative semantic features.With our method, a 3D CNN model pre-trained on $10^4$ multi-site healthy brain MRI scans can extract relevant features for three classification tasks: schizophrenia, bipolar diagnosis and Alzheimer's detection. When fine-tuned, it also outperforms 3D CNN trained from scratch on these tasks, as well as state-of-the-art self-supervised methods. Our code is made publicly available here.
* MICCAI 2021
Benchmarking CNN on 3D Anatomical Brain MRI: Architectures, Data Augmentation and Deep Ensemble Learning
Jun 02, 2021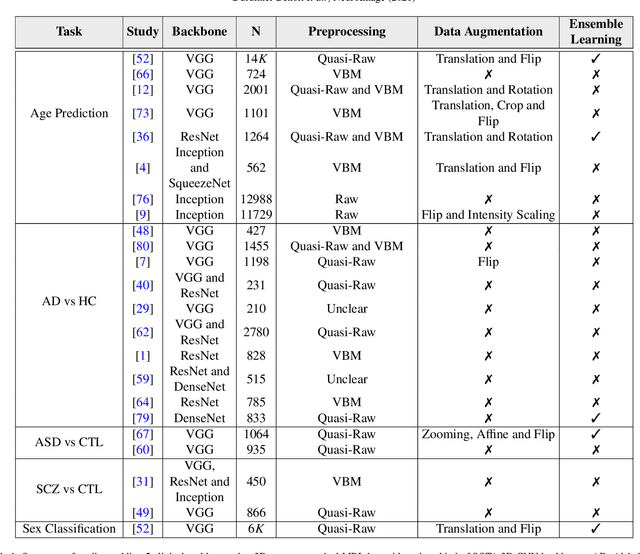
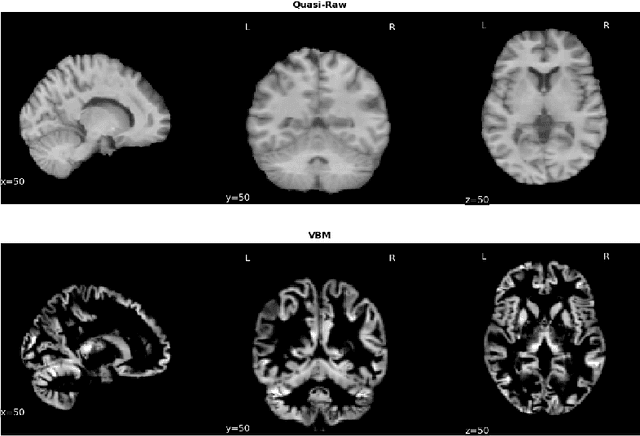
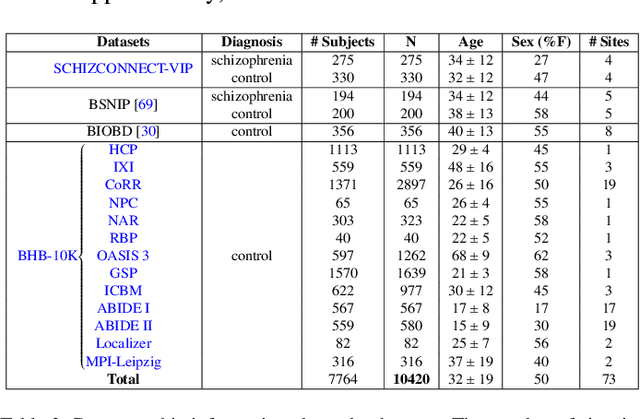
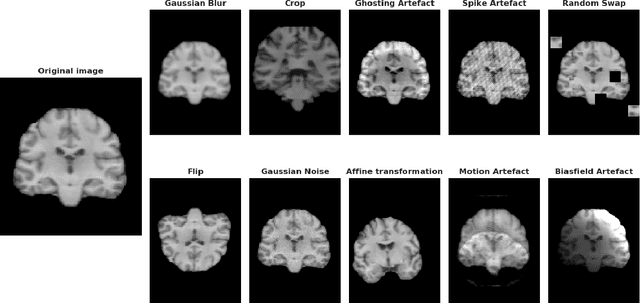
Deep Learning (DL) and specifically CNN models have become a de facto method for a wide range of vision tasks, outperforming traditional machine learning (ML) methods. Consequently, they drew a lot of attention in the neuroimaging field in particular for phenotype prediction or computer-aided diagnosis. However, most of the current studies often deal with small single-site cohorts, along with a specific pre-processing pipeline and custom CNN architectures, which make them difficult to compare to. We propose an extensive benchmark of recent state-of-the-art (SOTA) 3D CNN, evaluating also the benefits of data augmentation and deep ensemble learning, on both Voxel-Based Morphometry (VBM) pre-processing and quasi-raw images. Experiments were conducted on a large multi-site 3D brain anatomical MRI data-set comprising N=10k scans on 3 challenging tasks: age prediction, sex classification, and schizophrenia diagnosis. We found that all models provide significantly better predictions with VBM images than quasi-raw data. This finding evolved as the training set approaches 10k samples where quasi-raw data almost reach the performance of VBM. Moreover, we showed that linear models perform comparably with SOTA CNN on VBM data. We also demonstrated that DenseNet and tiny-DenseNet, a lighter version that we proposed, provide a good compromise in terms of performance in all data regime. Therefore, we suggest to employ them as the architectures by default. Critically, we also showed that current CNN are still very biased towards the acquisition site, even when trained with N=10k multi-site images. In this context, VBM pre-processing provides an efficient way to limit this site effect. Surprisingly, we did not find any clear benefit from data augmentation techniques. Finally, we proved that deep ensemble learning is well suited to re-calibrate big CNN models without sacrificing performance.