 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung Cancer Concept Annotation from Spanish Clinical Narratives
Sep 18, 2018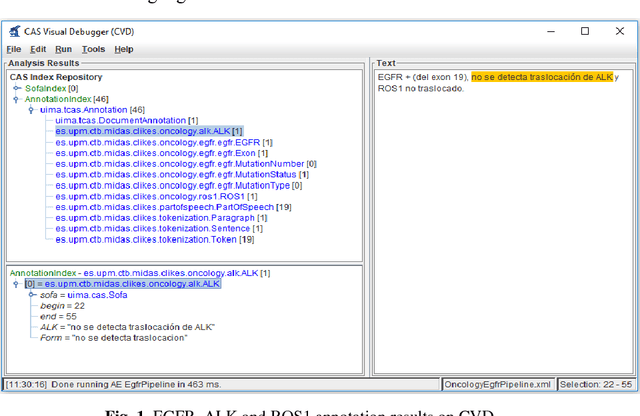

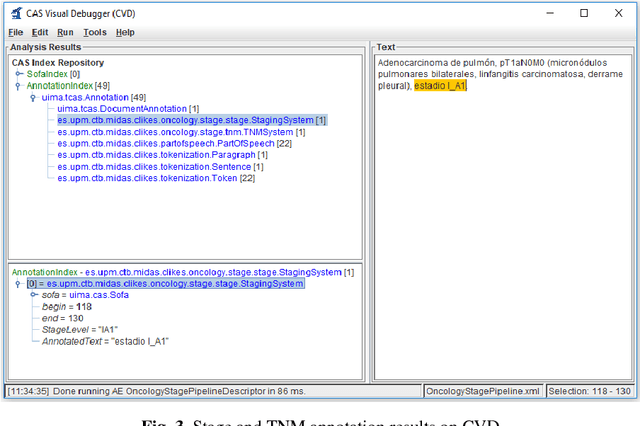
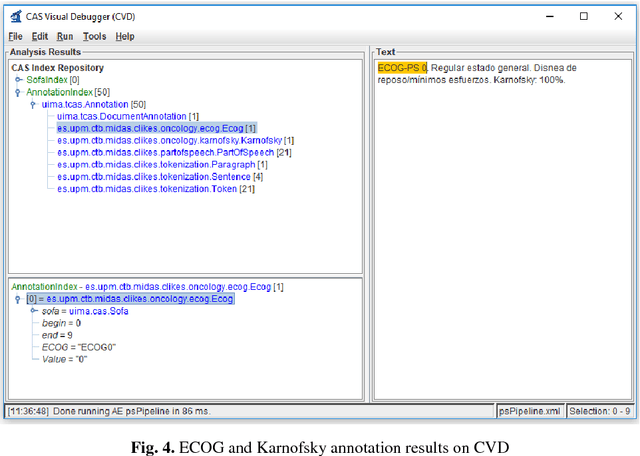
Recent rapid increase in the generation of clinical data and rapid development of computational science make us able to extract new insights from massive datasets in healthcare industry. Oncological clinical notes are creating rich databases for documenting patients history and they potentially contain lots of patterns that could help in better management of the disease. However, these patterns are locked within free text (unstructured) portions of clinical documents and consequence in limiting health professionals to extract useful information from them and to finally perform Query and Answering (QA) process in an accurate way. The Information Extraction (IE) process requires Natural Language Processing (NLP) techniques to assign semantics to these patterns. Therefore, in this paper, we analyze the design of annotators for specific lung cancer concepts that can be integrated over Apache Unstructured Information Management Architecture (UIMA) framework. In addition, we explain the details of generation and storage of annotation outcomes.
* 10 pages, 6 figures