 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Framework for Incorporating Patient Preferences Into Q-Learning
Jul 22, 2023
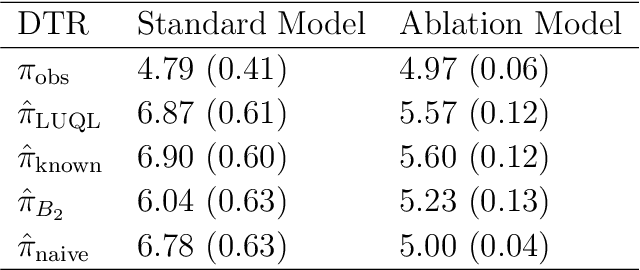


In real-world healthcare problems, there are often multiple competing outcomes of interest, such as treatment efficacy and side effect severity. However, statistical methods for estimating dynamic treatment regimes (DTRs) usually assume a single outcome of interest, and the few methods that deal with composite outcomes suffer from important limitations. This includes restrictions to a single time point and two outcomes, the inability to incorporate self-reported patient preferences and limited theoretical guarantees. To this end, we propose a new method to address these limitations, which we dub Latent Utility Q-Learning (LUQ-Learning). LUQ-Learning uses a latent model approach to naturally extend Q-learning to the composite outcome setting and adopt the ideal trade-off between outcomes to each patient. Unlike previous approaches, our framework allows for an arbitrary number of time points and outcomes, incorporates stated preferences and achieves strong asymptotic performance with realistic assumptions on the data. We conduct simulation experiments based on an ongoing trial for low back pain as well as a well-known completed trial for schizophrenia. In all experiments, our method achieves highly competitive empirical performance compared to several alternative baselines.
Revisiting Bellman Errors for Offline Model Selection
Jan 31, 2023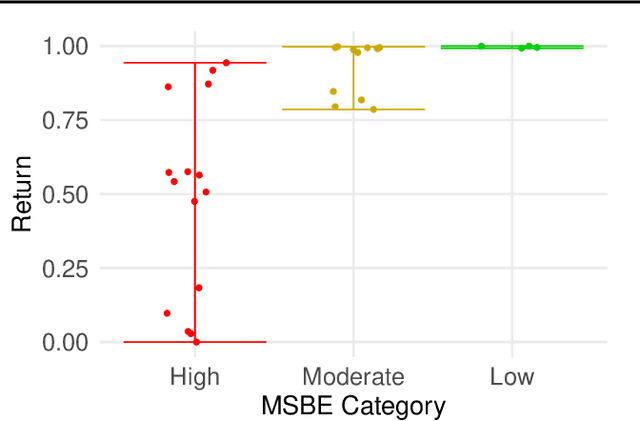
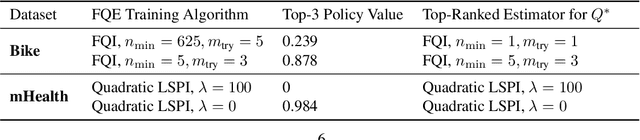
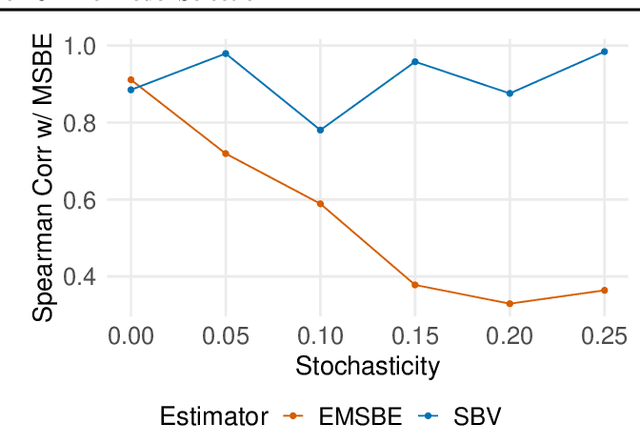

Offline model selection (OMS), that is, choosing the best policy from a set of many policies given only logged data, is crucial for applying offline RL in real-world settings. One idea that has been extensively explored is to select policies based on the mean squared Bellman error (MSBE) of the associated Q-functions. However, previous work has struggled to obtain adequate OMS performance with Bellman errors, leading many researchers to abandon the idea. Through theoretical and empirical analyses, we elucidate why previous work has seen pessimistic results with Bellman errors and identify conditions under which OMS algorithms based on Bellman errors will perform well. Moreover, we develop a new estimator of the MSBE that is more accurate than prior methods and obtains impressive OMS performance on diverse discrete control tasks, including Atari games. We open-source our data and code to enable researchers to conduct OMS experiments more easily.