Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition with Semantics
Oct 19, 2022
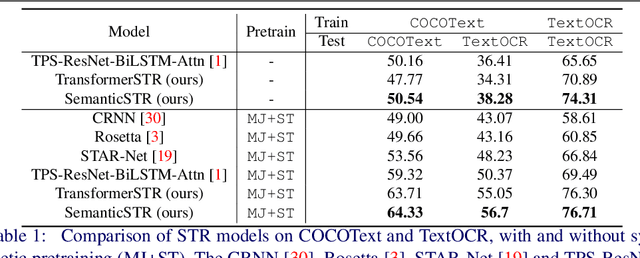
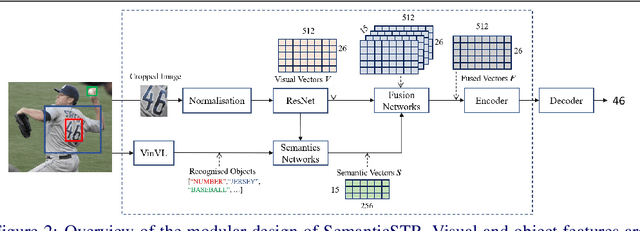
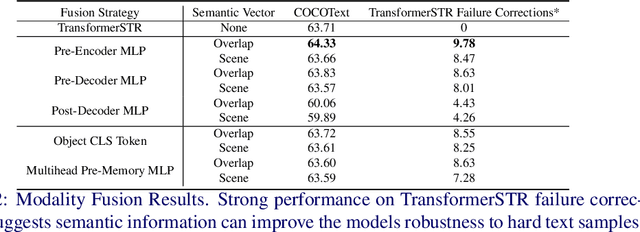
Scene Text Recognition (STR) models have achieved high performance in recent years on benchmark datasets where text images are presented with minimal noise. Traditional STR recognition pipelines take a cropped image as sole input and attempt to identify the characters present. This infrastructure can fail in instances where the input image is noisy or the text is partially obscured. This paper proposes using semantic information from the greater scene to contextualise predictions. We generate semantic vectors using object tags and fuse this information into a transformer-based architecture. The results demonstrate that our multimodal approach yields higher performance than traditional benchmark models, particularly on noisy instances.
* 11 pages, 7 figures
Via