 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridnet for depth estimation and semantic segmentation
Feb 09, 2024



Semantic segmentation and depth estimation are two important tasks in the area of image processing. Traditionally, these two tasks are addressed in an independent manner. However, for those applications where geometric and semantic information is required, such as robotics or autonomous navigation,depth or semantic segmentation alone are not sufficient. In this paper, depth estimation and semantic segmentation are addressed together from a single input image through a hybrid convolutional network. Different from the state of the art methods where features are extracted by a sole feature extraction network for both tasks, the proposed HybridNet improves the features extraction by separating the relevant features for one task from those which are relevant for both. Experimental results demonstrate that HybridNet results are comparable with the state of the art methods, as well as the single task methods that HybridNet is based on.
Pedestrian Detection in 3D Point Clouds using Deep Neural Networks
May 03, 2021
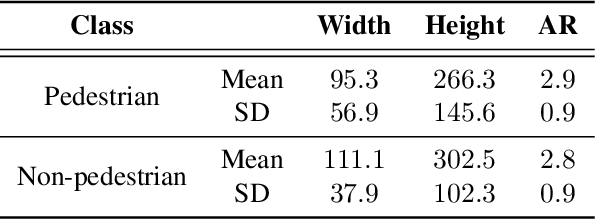
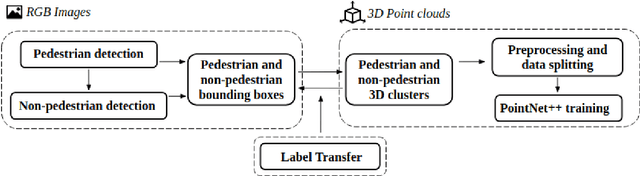
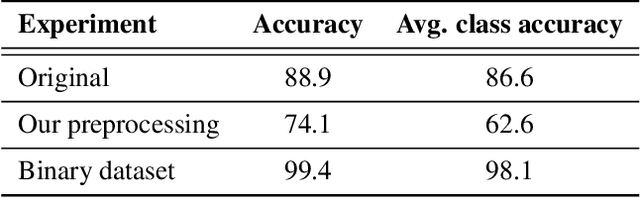
Detecting pedestrians is a crucial task in autonomous driving systems to ensure the safety of drivers and pedestrians. The technologies involved in these algorithms must be precise and reliable, regardless of environment conditions. Relying solely on RGB cameras may not be enough to recognize road environments in situations where cameras cannot capture scenes properly. Some approaches aim to compensate for these limitations by combining RGB cameras with TOF sensors, such as LIDARs. However, there are few works that address this problem using exclusively the 3D geometric information provided by LIDARs. In this paper, we propose a PointNet++ based architecture to detect pedestrians in dense 3D point clouds. The aim is to explore the potential contribution of geometric information alone in pedestrian detection systems. We also present a semi-automatic labeling system that transfers pedestrian and non-pedestrian labels from RGB images onto the 3D domain. The fact that our datasets have RGB registered with point clouds enables label transferring by back projection from 2D bounding boxes to point clouds, with only a light manual supervision to validate results. We train PointNet++ with the geometry of the resulting 3D labelled clusters. The evaluation confirms the effectiveness of the proposed method, yielding precision and recall values around 98%.
Graph based Dynamic Segmentation of Generic Objects in 3D
Apr 17, 2019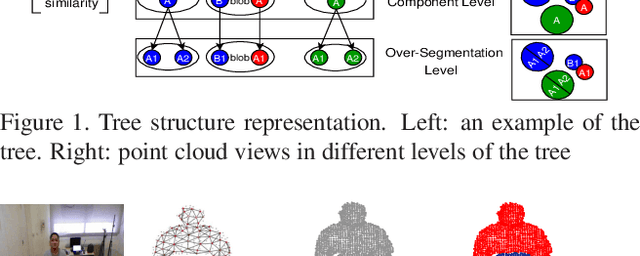

We propose a novel 3D segmentation method for RBGD stream data to deal with 3D object segmentation task in a generic scenario with frequent object interactions. It mainly contributes in two aspects, while being generic and not requiring initialization: firstly, a novel tree structure representation for the point cloud of the scene is proposed. Then, a dynamic manangement mechanism for connected component splits and merges exploits the tree structure representation.