 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Surveillance for Road Traffic Monitoring
May 11, 2021
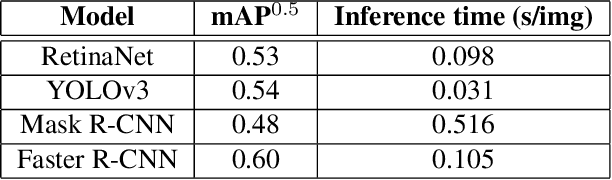

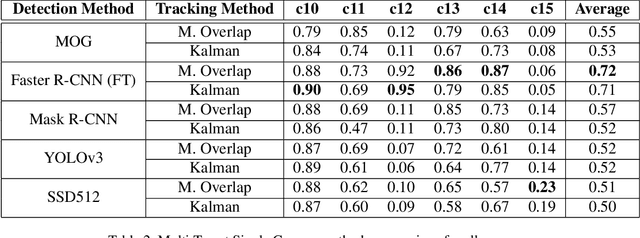
This paper presents the learned techniques during the Video Analysis Module of the Master in Computer Vision from the Universitat Aut\`onoma de Barcelona, used to solve the third track of the AI-City Challenge. This challenge aims to track vehicles across multiple cameras placed in multiple intersections spread out over a city. The methodology followed focuses first in solving multi-tracking in a single camera and then extending it to multiple cameras. The qualitative results of the implemented techniques are presented using standard metrics for video analysis such as mAP for object detection and IDF1 for tracking. The source code is publicly available at: https://github.com/mcv-m6-video/mcv-m6-2021-team4.
Scene Understanding for Autonomous Driving
May 11, 2021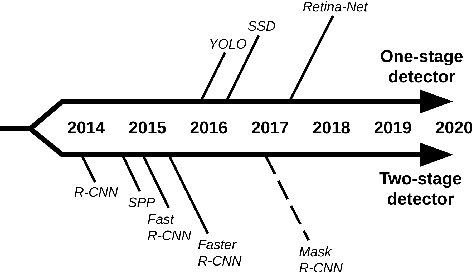

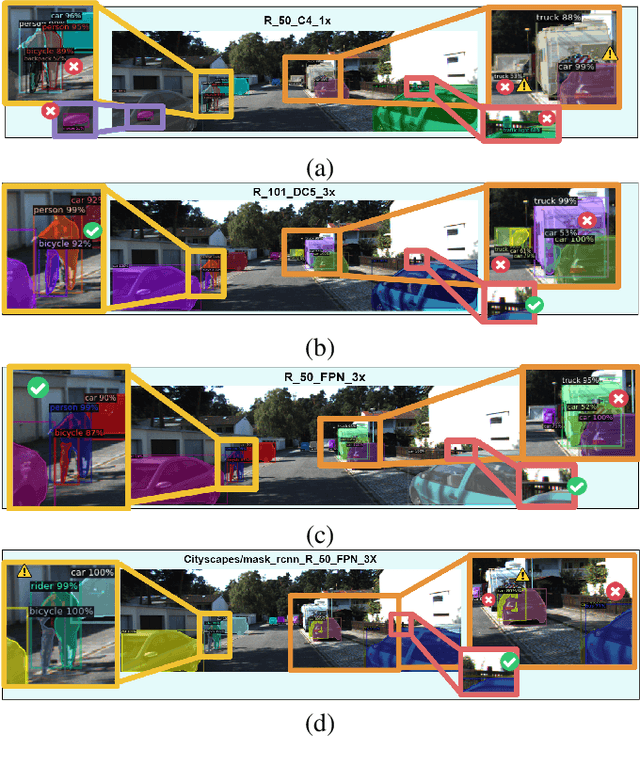
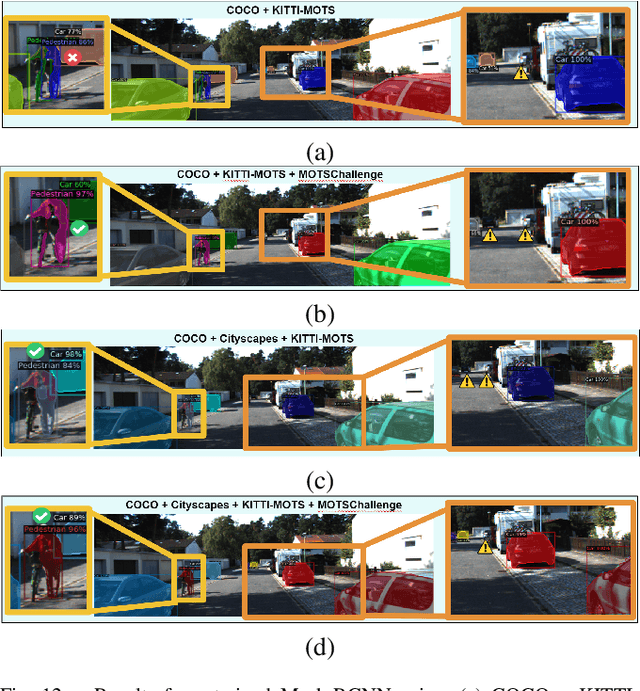
To detect and segment objects in images based on their content is one of the most active topics in the field of computer vision. Nowadays, this problem can be addressed using Deep Learning architectures such as Faster R-CNN or YOLO, among others. In this paper, we study the behaviour of different configurations of RetinaNet, Faster R-CNN and Mask R-CNN presented in Detectron2. First, we evaluate qualitatively and quantitatively (AP) the performance of the pre-trained models on KITTI-MOTS and MOTSChallenge datasets. We observe a significant improvement in performance after fine-tuning these models on the datasets of interest and optimizing hyperparameters. Finally, we run inference in unusual situations using out of context datasets, and present interesting results that help us understanding better the networks.
Image Classification with Classic and Deep Learning Techniques
May 11, 2021
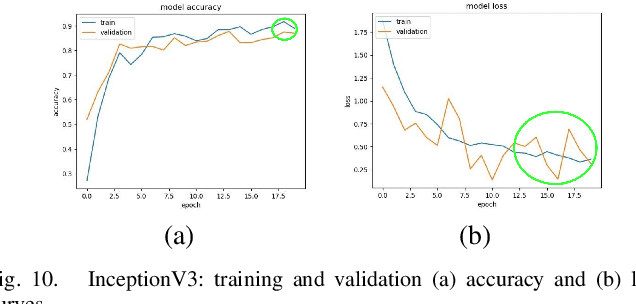
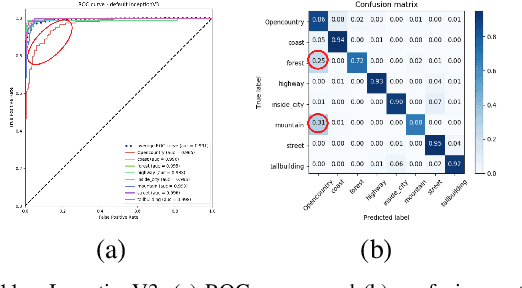
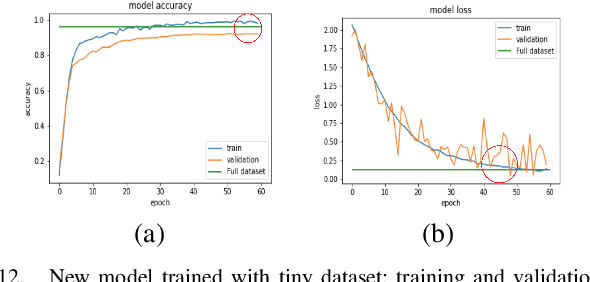
To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning techniques. Specifically, we study the performance of a Bag of Visual Words classifier using Support Vector Machines, a Multilayer Perceptron, an existing architecture named InceptionV3 and our own CNN, TinyNet, designed from scratch. We evaluate each of the cases in terms of accuracy and loss, and we obtain results that vary between 0.6 and 0.96 depending on the model and configuration used.
Museum Painting Retrieval
May 11, 2021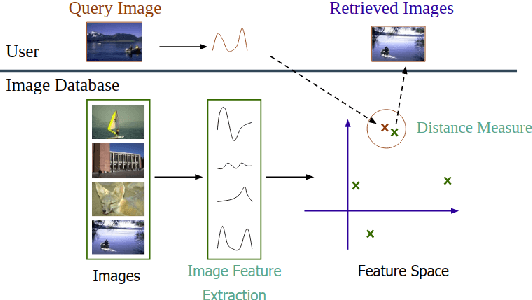

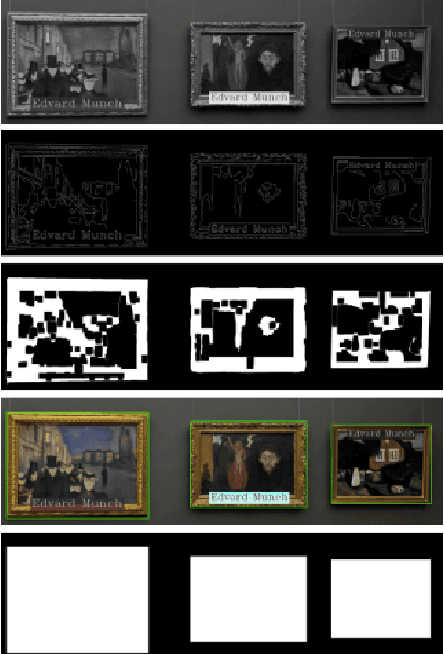

To retrieve images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as feature extraction using machine learning, but over the years different classical methods have been developed. In this paper, we implement a query by example retrieval system for finding paintings in a museum image collection using classic computer vision techniques. Specifically, we study the performance of the color, texture, text and feature descriptors in datasets with different perturbations in the images: noise, overlapping text boxes, color corruption and rotation. We evaluate each of the cases using the Mean Average Precision (MAP) metric, and we obtain results that vary between 0.5 and 1.0 depending on the problem conditions.
Pedestrian Detection in 3D Point Clouds using Deep Neural Networks
May 03, 2021
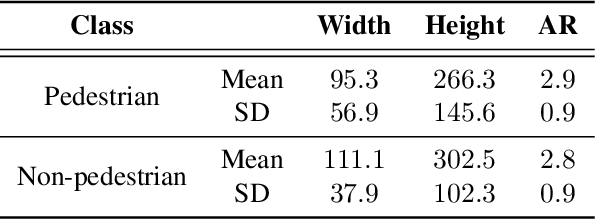
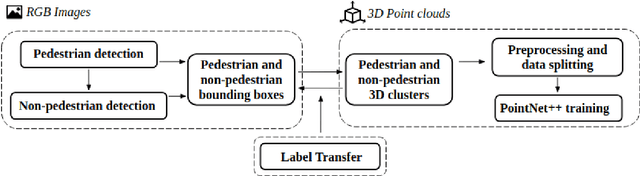
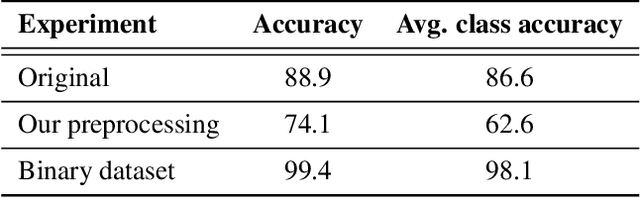
Detecting pedestrians is a crucial task in autonomous driving systems to ensure the safety of drivers and pedestrians. The technologies involved in these algorithms must be precise and reliable, regardless of environment conditions. Relying solely on RGB cameras may not be enough to recognize road environments in situations where cameras cannot capture scenes properly. Some approaches aim to compensate for these limitations by combining RGB cameras with TOF sensors, such as LIDARs. However, there are few works that address this problem using exclusively the 3D geometric information provided by LIDARs. In this paper, we propose a PointNet++ based architecture to detect pedestrians in dense 3D point clouds. The aim is to explore the potential contribution of geometric information alone in pedestrian detection systems. We also present a semi-automatic labeling system that transfers pedestrian and non-pedestrian labels from RGB images onto the 3D domain. The fact that our datasets have RGB registered with point clouds enables label transferring by back projection from 2D bounding boxes to point clouds, with only a light manual supervision to validate results. We train PointNet++ with the geometry of the resulting 3D labelled clusters. The evaluation confirms the effectiveness of the proposed method, yielding precision and recall values around 98%.